- Home
- Categorie
- Digital Marketing
- SEO
- Il casino di Google con i Title delle pagine e la pessima proposta di Danny Sullivan
-
@amine-el-fadil grazie tante
")
Come è bello leggere questa discussione e vedere le nostre evoluzioni e scoperte così ordinate.
È una soddisfazione: pensa a chi deve informarsi sul tema, qui è tuto ordinato, ne guadagna la cultura di un intero settore.

-
@aledandrea ancora no, fa ci farò attenzione. Ho pochissimi blog di quel tipo
-
@amine-el-fadil su un prospect, title e h1 uguali e Google prendeva dall'H4 (che non aveva senso avere messo h4).
A 1 Risposta -
@merlinox ha detto in Il casino di Google con i Title delle pagine e la pessima proposta di Danny Sullivan:
@amine-el-fadil su un prospect, title e h1 uguali e Google prendeva dall'H4 (che non aveva senso avere messo h4).
Ho parlato per questo di probabilità e non certezza. Alla fine è sempre Google a decidere.
Forse, ma lo devo testare, anche i links interni verso l'articolo possono fungere da conferma della bontà del title.
Ho alcuni title molto spinti, che sono confermati sia dal titolo ma anche da links interni, che hanno come ancora l'intero title. Questi title sono stati mantenuti.
Da studiare e testare, alla fine come detto prima è sempre Google il giudice finale, noi possiamo solo aumentare le chance che tenga il nostro lavoro.
-
Google che riscrive i titoli.... di google.... Fantastico! ^_^
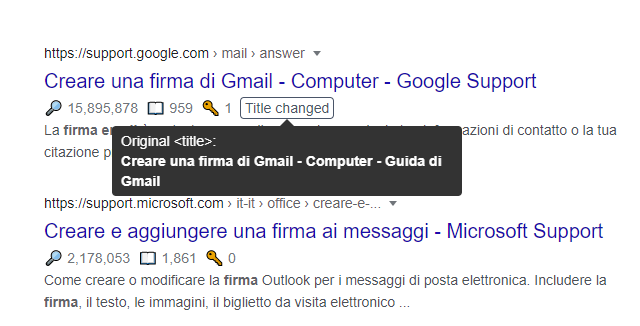
IA Vs Human 1 - 0
1 Risposta
-
1 Risposta
-
@sermatica Keyword Surfer....
Uno dei plug-in SEO che utilizzo
https://chrome.google.com/webstore/detail/keyword-surfer/bafijghppfhdpldihckdcadbcobikaca
-
Il problema è: il title cambia in base alla query. Quante volte, per ogni pagina, il nostro titolo cambia?
La faccenda è incontrollabile secondo me, anche se ci fosse il tool (e ci sarà), sarebbe impossibile lavorare tutti quei dati. Quindi più che altro dovremmo capire dei motivi generici per cui, per il nostro sito, cambia.
Un bel casino

1 Risposta
-
@giorgiotave Sistrix lo monitora, ma al controllo quotidiano. L'unico che può è GSC!
-
L'inizio obiettivamente non è dei più incoraggianti.
Le avanzatissime tecniche di Machine Learning conducono per il momento a roba come questa:
https://twitter.com/martinomosna/status/1434403324850282500
Che insomma, fa abbastanza ridere.
Oppure anche questo dei primi giorni che è clamoroso ed hanno dovuto fixarlo di corsa A MANO per ovvi motivi:
https://twitter.com/thetafferboy/status/1428313465106599937
Io credo che più che penalizzazioni o complotti la spiegazione sia solo una: chi ha preparato questo update ha fatto vedere ai responsabili superiori solo i risultati fighi e "azzeccati", ottenuti in un set di dati già accuratamente preparato e "pulito" in precedenza, evitando accuratamente di mostrare errori o scivoloni.
I responsabili hanno dato via libera, l'algoritmo è stato rilasciato nell'ambiente caotico che è il web ed i risultati hanno iniziato ad apparire sotto gli occhi dei SEO che hanno fatto esattamente il contrario degli ingegneri di cui sopra: hanno iniziato a fare una raccolta degli sfrondoni ASSOLUTI che sto algoritmo del menga ha fatto e sta continuando a fare.
Non è una penalizzazione.
È Google che ha rilasciato un aggiornamento "alla cazzo di cane" (Gianluca Campo su Twitter è stato più gentile di me parlando di metodologie Lean che poi è la stessa cosa
 ).
).La mia opinione per il momento è che quando riscrive, per il momento riscrive MALE.
Ma male male male.
Male tipo così: https://twitter.com/carlhendy/status/1431283991693438982
Migliorerà? Chissà. Vedremo.
1 Risposta
-
@kal loro lo fanno perché sono gentili.
Visto che non vogliono che noi facciamo errori su larga scala (https://twitter.com/dannysullivan/status/1428771675001163780) allora li fanno loro per noi.
1 Risposta
-
@juanin ha detto in Il casino di Google con i Title delle pagine e la pessima proposta di Danny Sullivan:
@kal loro lo fanno perché sono gentili.
Visto che non vogliono che noi facciamo errori su larga scala (https://twitter.com/dannysullivan/status/1428771675001163780) allora li fanno loro per noi.
Questa m'ha ribaltato:
https://twitter.com/dannysullivan/status/1430588046785748994
Ora, noi sappiamo bene che se c'è una violazione legale, vieni messo a torchio anche per quello che si trova su Google. Perché il giudice se ne sbatte dei tecnicismi: vede l'anteprima e giudica su quella.
Già solo questo basterebbe.
E poi c'è il carico: forse che Danny Sullyvan sta davvero suggerendo che Google debba essere ritenuto legalmente responsabile per gli strafalcioni che stanno sul suo sito?!?!?
Sarebbe epocale.
-
@kal Danny Sullivan come tutti i Googler fin tanto che sono dipendenti di Google si trasferiscono sulla torre d'avorio ignari di quello che succede nel mondo reale.
Perché anche un demente ne comprende facilmente le implicazioni.
Devono per forza fare finta di non capire perché è troppo banale.
-
Ok ragazzi, capolavoro assoluto: https://twitter.com/charlesmeaden/status/1434886965376294918
Secondo me fanno rollback entro 48h.
-
@kal qui ci vuole un RT
-
Non aggiungo altro. Quando misuri certe cose solo considerando i numeri...
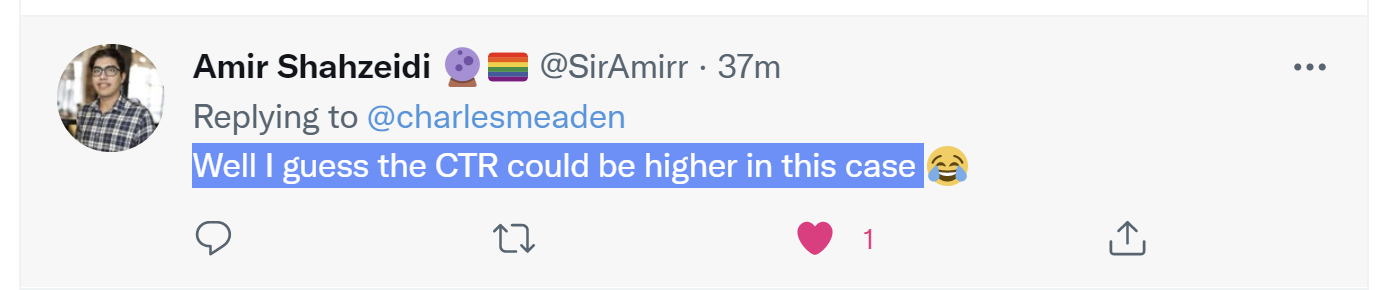
-
Aggiungo anch'io un paio di elementi che ho notato.
1 - Ho notato che in alcuni casi i titoli sono diversi da mobile o da desktop.
Un esempio:
Mobile: "Cos'è Gatsby? Un esempio di quello che serve oggi nello sviluppo web!"
Desktop: "Un esempio di quello che serve oggi nello sviluppo web!" (sembra la risposta nel title diretta, ma è completamente decontestualizzata, secondo me)
Tag Title = H1 = "Cos'è Gatsby? Un esempio di quello che serve oggi nello sviluppo web!"2- Quando modifica il title, usa gli heading e tendenzialmente l'H1, ma...
C'è stato un caso che mi ha fatto riflettere, ed è quello condiviso da Wordstream. Premetto che non approvo la struttura dei tag heading che usano in pagina. Ma si nota come, in presenza di più H1, va a prendersi quello che ritiene il titolo del main content (NOTA DETERMINANTE: quando c'è stato l'update la pagina era così: https://web.archive.org/web/20210812185930/https://www.wordstream.com/keywords ). Infatti, tra i diversi H1 (non commento la struttura) si prende quello dove effettivamente c'è il contenuto.
Non è di certo un miglioramento della UX (l'esempio è lampante), ma è una constatazione che sembra scontata in una pagina di un blog, ma meno in una pagina come quella in esame.
Quindi attenzione alla coerenza che l'algoritmo prova a cercare tra titoli, struttura della pagina.
-
Ho visto il video di @giorgiotave sull'argomento e mi ha solleticato due temi che mi sono sempre stati a cuore:
- I professionisti SEO. Ovviamente fa piacere che (finalmente) anche Google parli di professionisti SEO e non più solo di Webmaster. Ci sono voluti 20 anni! Peraltro era uno dei temi forti che ponevamo ai motori di ricerca quando esisteva SEMPO, l'associazione internazionale delle agenzie search, oggi purtroppo defunta e invece ancora necessaria a mio parere (magari con una struttura più moderna)
- l SEO migliorano i motori di ricerca. Lo affermavo già ai tempi delle doorway pages e continuo a crederlo, ovviamente al netto delle tecniche black hat. Si dovrebbe fare di più per farlo capire in giro.
Poi magari un giorno, vi racconto off the record cosa ci dicevamo con Danny Sullivan a proposito di come arginare il potere dei motori di ricerca nei confronti delle agenzie...

2 Risposte
-
Per la cronaca, "Tax avoidance" sta ancora lì!! Provare per credere.
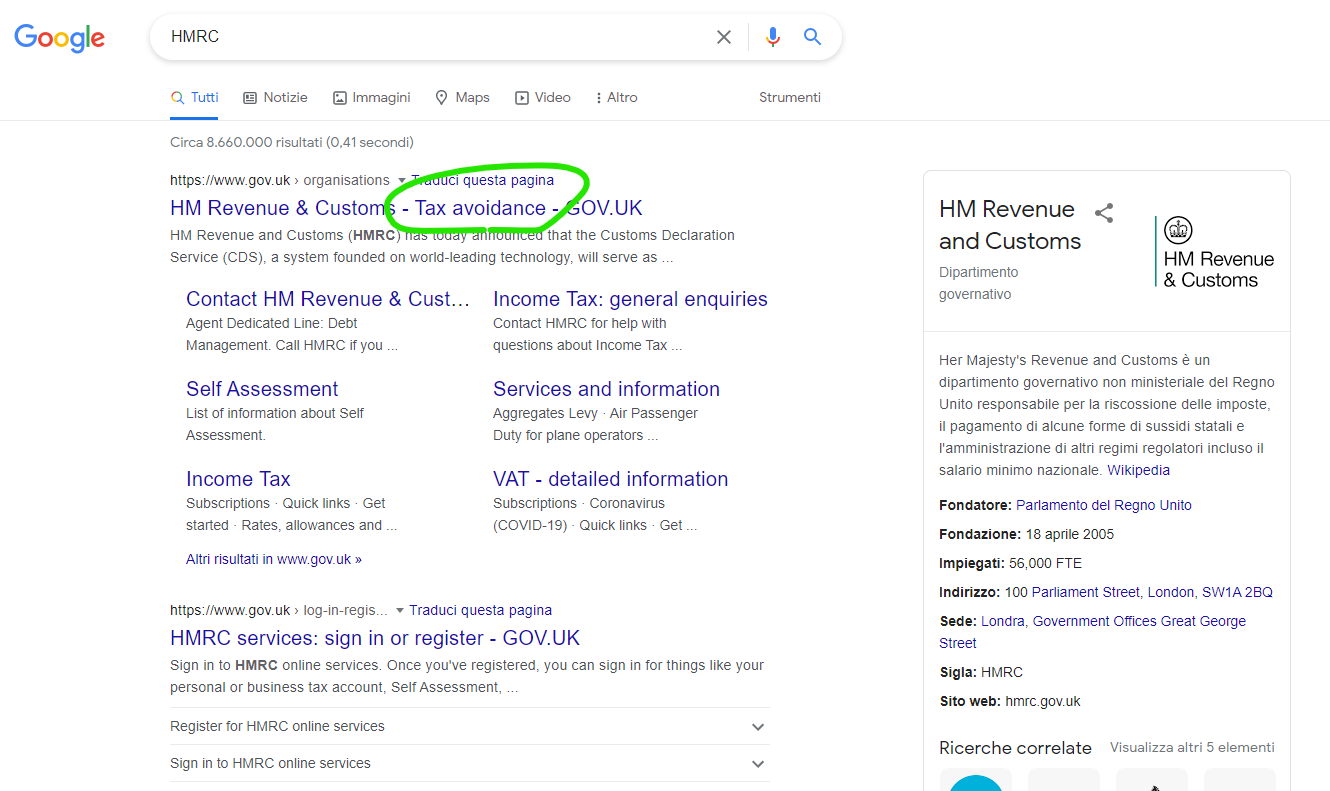
Cioè, è come se cercando "AdE" su Google comparisse come titolo "Agenzia delle Entrate - Elusione fiscale".
Ma ditemi voi

-
@maurolupi e purtroppo Danny Sullivan ora è diventato parte del problema

Come cambiano i tempi...