- Home
- Categorie
- Digital Marketing
- SEO
- Il Test su Discover di Connect.gt
-
@alepom ha detto in Il Test su Discover di Connect.gt:
E' comparso dopo un picco di impression e clic dovute al posizionamento di un post su un argomento particolarmente in trend in un determinato periodo.
Osservazione estremamente utile che in qualche modo conferma quanto ho appena scritto, ovvero: c'entrano i trend delle ricerche.
Dovremmo provare a riprodurre l'esperimento fatto finora, con però alcuni accorgimenti in più.
- il contenuto deve essere progettato e prodotto prendendo di mira una query che Google Trends identifica come "Impennata" all'interno di un argomento
- l'argomento scelto dovrà essere pubblicato su un sito web o da un profilo con buona "topical authority" su quell'argomento
Ad esempio: non credo che sia un caso che Giorgio sia riuscito a bucare Discover con questi due argomenti qua:
@giorgiotave ha detto in Il Test su Discover di Connect.gt:
https://twitter.com/giorgiotave/status/1324654047144615939
https://twitter.com/giorgiotave/status/1327307108115746816Mentre il primo test l'abbiamo fatto su un argomento differente:
Focus su Amazon.
Ed il secondo pure:
Focus sui Social.
Ma @giorgiotave è un'autorità riconosciuta principalmente per Google e SEO.
Nel tuo caso invece @alepom direi quasi certamente non c'era un pubblico ricettivo "pronto" a ricevere il contenuto che abbiamo spinto.
-
Questa devo scriverla perché mi è appena capitata ed è pazzesca. Sento che siamo a tanto così dal capire come funziona davvero Discover.
Allora, premessa: ho un portatile che è fermo alla versione 1909 di Windows 10.
Ieri mattina mia figlia più grande lo usa per fare la DaD e vedo un messaggio in area di notifica: "sta per terminare il supporto, aggiorna subito". Tipo questo:

E penso: ma che cavolo. Devo aggiornarlo all'ultima versione.
Nel tardo pomeriggio mi metto all'opera, ma sulla schermata di aggiornamento a quanto pare manca il pulsante di aggiornamento. Al suo posto, mi becco l'equivalente di questo:
![[Immagine Windows aggiornamento]](https://images.idgesg.net/images/article/2021/03/2004block-100880828-large.jpg)
Clicco sul link "Learn more" per vedere dove mi porta, e mi porta a questo URL:
URL che fa un redirect verso questa pagina.
https://docs.microsoft.com/it-it/windows/release-health/status-windows-10-2004
Penso: uff, e adesso come la risolvo?
Mi mancava il tempo per fare ricerche su Google, era il passo successivo... Ma ho rinunciato per quel momento.
Ed ora, rullo di tamburi... Che cosa mi sono ritrovato in Discover dopo un paio d'ore?
Mi ritrovo questo:
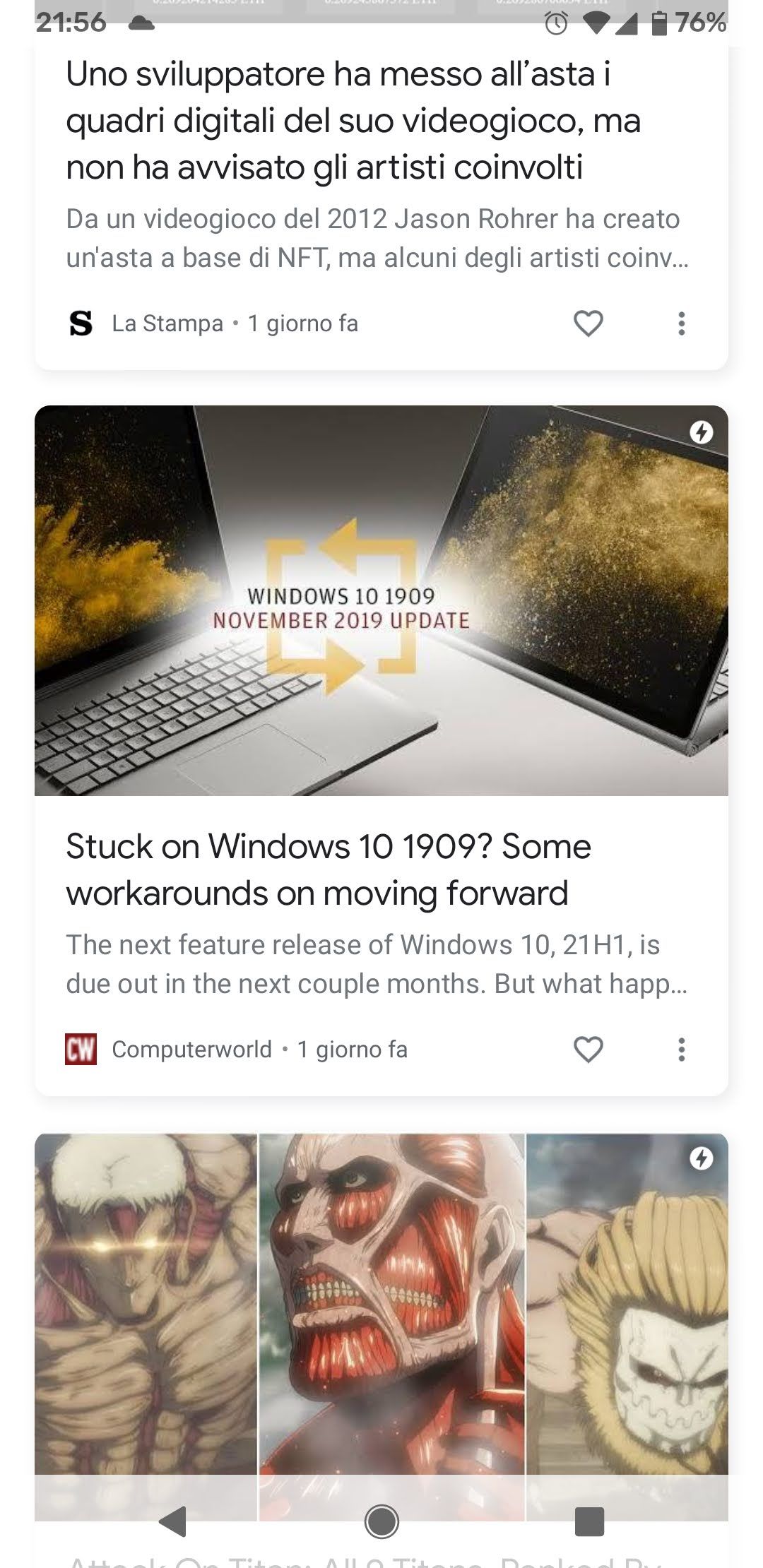
L'articolo in questione: https://www.computerworld.com/article/3611672/stuck-on-windows-10-1909-some-workarounds-on-moving-forward.html
Devo ancora verificare, ma a memoria mi pare che il portatile avesse proprio il driver incriminato. Quindi sembra proprio un articolo risolutivo!
Ci sono rimasto abbastanza di sasso sinceramente.
Direi che Google ha:
- Raccolto il mio dato clickstream di quell'URL particolare
- Messo il mio account Google (loggato su Chrome) in una coorte di utenti, presumo piuttosto nutrita a livello globale, che come me hanno visitato quell'URL
- Ha visto che molti di quella coorte hanno fatto delle ricerche (lo avrei fatto anche io come detto, ma ho rinunciato per mancanza di tempo)
- Ha visto che io non avevo fatto alcuna ricerca
- Mi ha sparato quell'articolo su Discover
Mi sembra un indizio fortissimo ed ho due osservazioni da fare:
- C'entrano SICURAMENTE le ricerche. Un contenuto non finisce su Discover senza che sia anche appetibile alla ricerca di query esistenti (e molto probabilmente trending, vedi sotto)
- Sento puzza di machine learning per definire le coorti di utenti
Il punto 2 complica non poco le cose e secondo me affossa un po' le speranze di fare un vero reverse engineering del processo.
Ma la 1 secondo me è il punto davvero dirimente.
Che ne pensate?
Ah, dimenticavo... perché quell'articolo e non un altro tra i mille che ci sono?
C'entra sicuramente il fatto che sia un articolo molto recente:
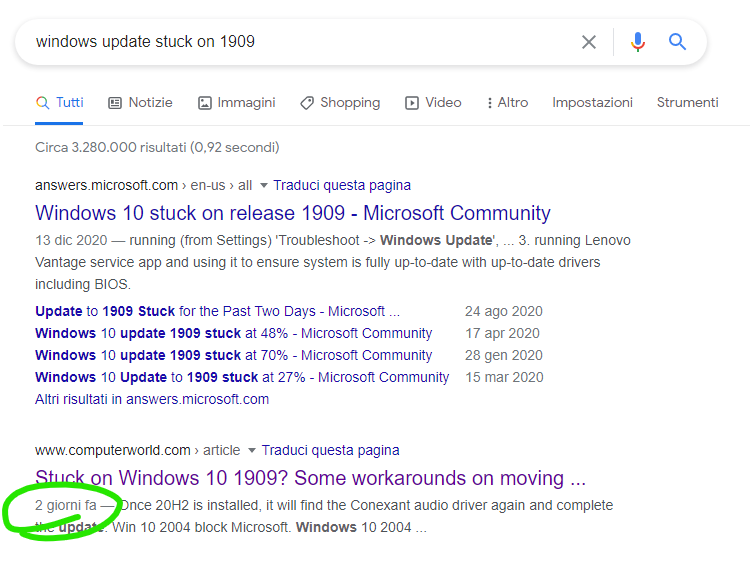
E già che ci sono, aggiungo un altro dettaglio, che riguarda proprio i trend...
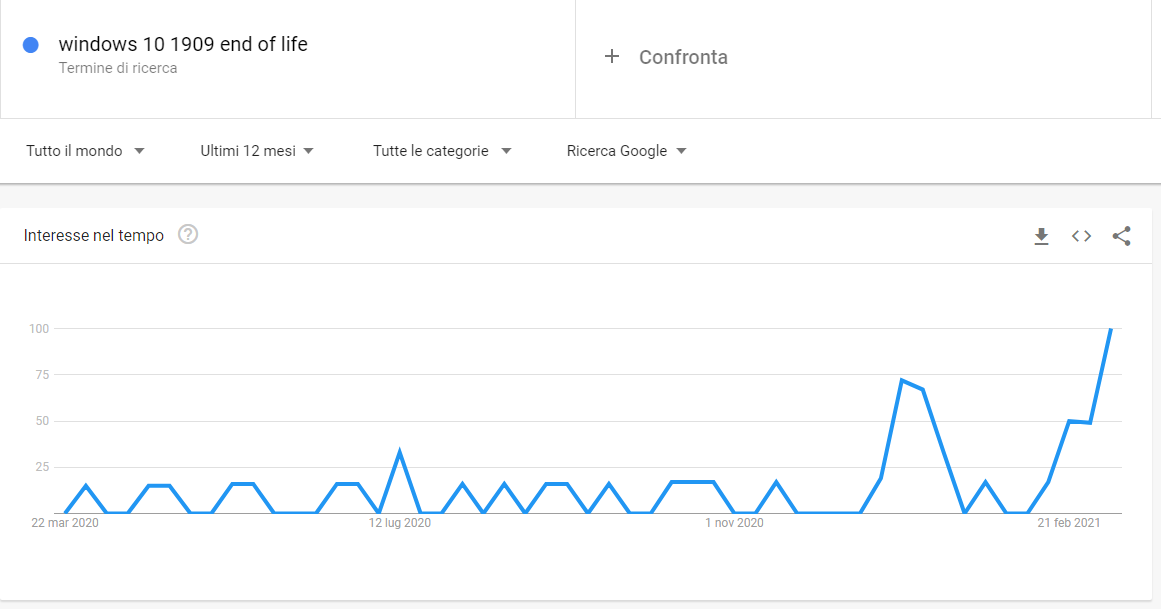
2 Risposte
-
@kal, che figata!
Quindi torna la questione del trend.
Chiaramente la parte relativa alla freschezza è in linea con quello che avevamo osservato.Sono d'accordo sulla questione della complessità algoritmica che c'è dietro.
1 Risposta
-
@alepom torna tutto, per questo è un esempio fichissimo. Ancora devo raccapezzarmi su come queste informazioni possano effettivamente tradursi poi in prassi editoriale.
Bisogna dire che imbroccare il trend non è una cosa semplicissima da fare in un esperimento... ma è sicuramente parte del lavoro quotidiano di una redazione giornalistica o para-giornalistica.
Però il mix da ottenere direi che a questo punto è chiaro:
- serve una ricerca trending
- serve produrre del contenuto che intercetti il trend
- servono dati clickstream che portino Google alla definizione di una coorte di utenti ampia a sufficienza da addestrare dei classificatori basati su rete neurale
I primi due punti sono lavoro che potremmo definire "SEO classico" per le redazioni web. Il punto 3 è il più difficile da crackare. Probabilmente comunque è "automatico" per tutti i siti di una certa popolarità. Da capire se ci possa essere margine per qualcosa di "spintaneo" per i siti più piccoli o meno popolari.
Vediamo se ci viene in mente come.
Anzi, proverei a:
- identifichiamo una ricerca trending ma sufficientemente di nicchia (difficilissimo!)
- produciamo un contenuto correlato
- facciamo la roba del clickstream, a questo punto non necessariamente da Twitter, va bene qualunque mezzo basta che sia un browser di Google
- facciamo ANCHE le ricerche trending individuate al punto 1, possibilmente se lo troviamo in SERP clicchiamo sul nostro contenuto esca
È tutto un po' confuso e non so quanto potremmo riuscire ad essere efficaci... se ci sono osservazioni sono le benvenute.
1 Risposta
-
@kal ha detto in Il Test su Discover di Connect.gt:
CHE CAVOLO HO APPENA LETTO
-
@giorgiotave è spaziale Giorgio.
Sono anche io un po' gasato, ma secondo me siamo davvero vicini a capire come funziona.
E saremmo i primi se ci riusciamo, perché quello che ho letto sull'internet internazionale in inglese è un generale brancolare nel buio, anche da parte di SEO "blasonati".
Vedi ad esempio questo recente articolo di Mordy Oberstein (è il SEO di Wix), che è poco più di un flusso di coscienza inconclusivo...
https://moz.com/blog/google-discover-experiment
E che si conclude con:
In other words, you can’t create content specifically for Discover. There’s no such concept. There’s no such control. There is no set of standardized “ranking signals” that you can try to optimize for.
Eh no caro Mordy. Noi di Connect.gt non siamo d'accordo

Sei solo tu che ti sei arreso.
-
Di certo non è semplice testarlo.
Io sto facendo un test perché ho un sito web con topic in trend e con conseguente picco di impression e clic su Search Console.Sito che è già comparso su Discover. E aspetta.. quando è comparso? Quando ci sono stati dei picchi di trend.
Si vede chiaramente dai dati.
E così è stato anche per il sito web che abbiamo usato per l'ultimo test.wow!
-
La butto:
@kal se @giorgiotave acconsente, per quel che concerne il punto 3, potremmo migliorare la condizione "30 click" che ci perseguita su Twitter, inserendo il link all'articolo nella sua newsletter (comunicando esplicitamente che si tratta di un test e di visitare per amor della ricerca l'articolo
 ).
).Avremmo così una riproduzione in scala di quanto ti è accaduto. La difficoltà maggiore a quel punto, sarebbe trovare la nicchia in trend da cavalcare e adeguato contenitore.
-
@brum secondo me il problema principale non è tanto la QUANTITÀ del traffico, quanto piuttosto la sua qualità.
Non saprei bene come spiegarmi... però la coorte di utenti che fa da seme per il segmento più generico di corrispondenza deve avere caratteristiche ben definite, in modo che l'algoritmo di raggruppamento e classificazione possa riconoscerlo come un insieme coerente.
Questo ha secondo me a che vedere con quanto scrivevo sopra, ovvero:
@kal ha detto in Il Test su Discover di Connect.gt:
Dovremmo provare a riprodurre l'esperimento fatto finora, con però alcuni accorgimenti in più.
- il contenuto deve essere progettato e prodotto prendendo di mira una query che Google Trends identifica come "Impennata" all'interno di un argomento
- l'argomento scelto dovrà essere pubblicato su un sito web o da un profilo con buona "topical authority" su quell'argomento
Ad esempio: non credo che sia un caso che Giorgio sia riuscito a bucare Discover con questi due argomenti qua:
@giorgiotave ha detto in Il Test su Discover di Connect.gt:
https://twitter.com/giorgiotave/status/1324654047144615939
https://twitter.com/giorgiotave/status/1327307108115746816Mentre il primo test l'abbiamo fatto su un argomento differente:
https://twitter.com/giorgiotave/status/1331236132571533315
Focus su Amazon.
Ed il secondo pure:https://twitter.com/giorgiotave/status/1361994102078902279
Focus sui Social.
Ma @giorgiotave è un'autorità riconosciuta principalmente per Google e SEO.
-
@kal mmm aspetta, anch'io facevo un ragionamento basato sulla qualità, ma supportato dalla quantità che fin'ora è mancata credo. Voglio capire meglio cosa intendi però.
Prendiamo quanto ti è accaduto con l'aggiornamento di Windows. Quali sono, seguendo il tuo pensiero, le caratteristiche che definivano gli utenti coinvolti e di conseguenza classificati come "gruppo coerente"?
-
@brum ha detto in Il Test su Discover di Connect.gt:
Prendiamo quanto ti è accaduto con l'aggiornamento di Windows. Quali sono, seguendo il tuo pensiero, le caratteristiche che definivano gli utenti coinvolti e di conseguenza classificati come "gruppo coerente"?
Utenti che hanno seguito questa semplice "user journey":
- hanno ricevuto la notifica di windows
- hanno aperto la schermata di update
- hanno cliccato sul messaggio atterrando sulla pagina incasinata del sito Microsoft che non aiuta per niente
- si son messi a cercare su Google informazioni su come risolvere il problema
E possiamo star tranquilli che nel 99,9% dei casi gli utenti abbiano fatto esattamente questa sequenza, perché è la più logica.
Io mi sono fermato al punto 3, avrei voluto fare il punto 4.
E Google mi ha anticipato su Discover.
Sapeva in altre parole che query avrei potuto fare sul motore di ricerca e mi ha presentato il contenuto tra i più recenti e popolari.
Ma lo sapeva perchè aveva dei dati PRECEDENTI relativi alla user journey che ho riassunto sopra.
Quindi la chiave secondo me è questa: si riesce a simulare una user journey che convinca Google a sparare un determinato contenuto su Discover?
Non servono numeri grandi, questo lo abbiamo stabilito visti i precedenti.
Serve piuttosto un focus molto preciso delle azioni utente eseguite.
E c'entra la ricerca su Google, anche.
-
@kal perfetto sono d'accordo con te.
Ora rimane solo la questione clickstream.
Nel caso relativo all'aggiornamento, tu hai visitato la pagina incasinata e da lì Google ti ha inserito nel gruppo a cui mostrare il contenuto su Discover.Sopra tu giustamente dicevi:
- facciamo la roba del clickstream, a questo punto non necessariamente da Twitter, va bene qualunque mezzo basta che sia un browser di Google
- facciamo ANCHE le ricerche trending individuate al punto 1, possibilmente se lo troviamo in SERP clicchiamo sul nostro contenuto esca
A questo punto quanto valore dai al clickstream? Per questo pensavo di forzarlo un pochino sfruttando un bacino più ampio.
-
@brum ha detto in Il Test su Discover di Connect.gt:
A questo punto quanto valore dai al clickstream?
Non è il volume, come detto, ma secondo me conta come vai a "sagomare" la user journey.
Ad esempio, mi viene in mente ora che forse bisogna fare PRIMA la ricerca su Google e poi cliccare. Meglio se il contenuto è proprio in SERP.
Si potrebbe provare anche a fare qualcosa coinvolgendo più persone... ma se la user journey è confusa e Google non riesce a comprendere la correlazione tra ricerche trending e coorte di utenti "estesa"... non ce ne facciamo nulla.
Non ho davvero idee concrete su come fare in pratica a costruire la cosa, purtroppo.
-
@kal ha detto in Il Test su Discover di Connect.gt:
Ad esempio, mi viene in mente ora che forse bisogna fare PRIMA la ricerca su Google e poi cliccare. Meglio se il contenuto è proprio in SERP.
Si potrebbe provare anche a fare qualcosa coinvolgendo più persone... ma se la user journey è confusa e Google non riesce a comprendere la correlazione tra ricerche trending e coorte di utenti "estesa"... non ce ne facciamo nulla.
Se attendiamo che il contenuto sia indicizzato, potremmo simulare la user journey in sostituzione al click diretto sul link...
X utenti effettuano una ricerca per query X (e relative) in trend e cliccano sul medesimo risultato.Alla fine il giochino scatta dal punto 3, il 4 è un'azione che tu non hai svolto tra l'altro, quindi non indispensabile:
- hanno cliccato sul messaggio atterrando sulla pagina incasinata del sito Microsoft che non aiuta per niente
- si son messi a cercare su Google informazioni su come risolvere il problema
Continuo a vedere il volume come un elemento a corredo, ma non insignificante.
-
@brum ha detto in Il Test su Discover di Connect.gt:
Continuo a vedere il volume come un elemento a corredo, ma non insignificante.
Il problema è il volume di cosa.
Il volume dei dati clickstream su un URL? Probabilmente basso. Abbiamo la newsletter di Giorgio che prova questa cosa. La newsletter normalmente non viene visualizzata sul web... ma è entrata in Discover nel momento in cui ha avuto risonanza su Twitter. Ma IN QUEL CONTESTO sono bastate poche decine di clic...
Il volume di ricerca sulle query che Discover prova ad anticipare?
Probabilmente questo è più rilevante.
Ma sono idee, non sappiamo davvero se esista una soglia e quanto grande.
-
@kal proprio nel caso di quella newsletter (sono andato a vedere, la numero 3), avevo letto il contenuto sul browser per puro caso. Il giorno successivo l'ho trovata in discover.
Non mi è più capitato di leggerle sul browser ne di trovarle in discover.Secondo me il volume dei dati clickstream su un URL ha il suo valore se correlato ad un trend in corso.
Tutta la spazzatura che trovo costantemente su discover con titoli clickbait ad esempio, quali query possono anticipare?
Hanno la quasi totalità del traffico proveniente dai social e gli articoli sono inesistenti. Se non per la mole di traffico che ricevono per un argomento in trend (calciatore, gossip, e simili) quali altre caratteristiche li spingono in discover?Ora non dico sia determinante, ma non riesco ad escluderlo totalmente.
Poi, se entriamo in discover, con o senza volume, festeggio volentieri
-
@brum ha detto in Il Test su Discover di Connect.gt:
Tutta la spazzatura che trovo costantemente su discover con titoli clickbait ad esempio, quali query possono anticipare?
Questa è un'ottima domanda. Provo a fare qualche ragionamento.
Sicuramente su Discover non c'è SOLO contenuto correlato a trend in corso. Ci sono anche articoli "nuovi" ma correlati al segmento di interesse delle varie coorti in cui ti ritrovi.
Io ad esempio ho un flusso costante di notizie astronomiche, che è una delle mie passioni. Oppure ad esempio i videogiochi in generale.
Quindi sicuramente c'è una meccanica per i contenuti di "ricerca latente" (chiamiamola così, è quella che mi è appena capitata con la storia dell'aggiornamento di Windows) e una per i contenuti legati al semplice interesse.
In entrambi i casi abbiamo comunque:
- contenuto fresco
- correlato ad un interesse (costante o emergente) di un pubblico sufficientemente ampio
EDIT: parlando di coorti di utenti, ho appena avuto un'illuminazione...
FLoC
È la proposta di Google per sostituire i cookie di terze parti per il targeting della pubblicità. Ma ha moltissime cose in comune con i discorsi che abbiamo fatto fin qua... e non credo per caso. Su Discover dopotutto ci sono gli annunci pubblicitari...
Questa frasetta è secondo me importante:
The browser uses machine learning algorithms to develop a cohort based on the sites that an individual visits. The algorithms might be based on the URLs of the visited sites, on the content of those pages, or other factors.
In altre parole: FLoC fa sì che sia il browser ad utilizzare i dati clickstream per generare delle coorti tramite machine learning.
Cioè ESATTAMENTE quello che abbiamo notato che fa Google.
-
@kal ha detto in Il Test su Discover di Connect.gt:
È la proposta di Google per sostituire i cookie di terze parti per il targeting della pubblicità. Ma ha moltissime cose in comune con i discorsi che abbiamo fatto fin qua... e non credo per caso. Su Discover dopotutto ci sono gli annunci pubblicitari...
Questo documento è interessantissimo. Ora, noi come infiliamo il nostro contenuto in queste righe?
if cohorts can be used for tracking, then having more interest cohort samples for a user will make it easier to reidentify them on other sites that have observed the same sequence of cohorts for a user.
Sostanzialmente descrive la tua esperienza con il "windows update".
Ma dice anche che oltre a questo:- contenuto fresco
- correlato ad un interesse (costante o emergente) di un pubblico sufficientemente ampio
il nostro contenuto dovrà essere identificabile, tra gli altri contenuti che appartengono alla stessa sequenza di coorti.
Nel caso del windows update, la selezione era semplice, perché l'articolo di computer world è l'unico fresco in relazione al trend e rispecchia le altre linee di cui abbiamo parlato.
Curati gli aspetti di cui sopra, se trovassimo bassa concorrenza sul contenuto fresco potrebbe essere un grosso aiuto per il nostro test.

Cosa dici, possiamo iniziare ad organizzare idee per il contenuto?
-
@brum ha detto in Il Test su Discover di Connect.gt:
Cosa dici, possiamo iniziare ad organizzare idee per il contenuto?
Sotto con le idee!
Anzi, sicuramente ne parliamo in live questo pomeriggio assieme a Giorgio, Alessio e Matteo.