- Home
- Categorie
- Digital Marketing
- SEO
- correlare schema attraverso @id
-
correlare schema attraverso @id
Salve, vorrei interpellare qualche esperto di schema perché non trovo risposta, ossia documentazione ufficiale, in merito a una cosa. Provo a coinvolgere @alepom @merlinox @kal se avranno voglia di dire la loro...
Intanto, ringrazio @alepom") perché gli schema di sytebysite e per la precisione del suo noto articolo sulla voice serach https://www.sitebysite.it/digital-strategy/cose-la-voice-search/ sono stati i "casi" su cui mi sono esercitato per la creazione dei miei schema, insieme a quelli di Jason Barnard, Lily Rye, Alessio Volpini (di Wordlift), insomma persone che mangiano schema a colazione.
perché gli schema di sytebysite e per la precisione del suo noto articolo sulla voice serach https://www.sitebysite.it/digital-strategy/cose-la-voice-search/ sono stati i "casi" su cui mi sono esercitato per la creazione dei miei schema, insieme a quelli di Jason Barnard, Lily Rye, Alessio Volpini (di Wordlift), insomma persone che mangiano schema a colazione.In generale, lo scrivo a favore di chi inizia a studiare schema, testare le pagine altrui col tool di Google su cui sapete che lavorano bravi SEO, è un ottimo modo di imparare, così come lo è l'estrazione dei JSON direttamente da HTML o URL di pagina fatta da tool come RankMath Pro.
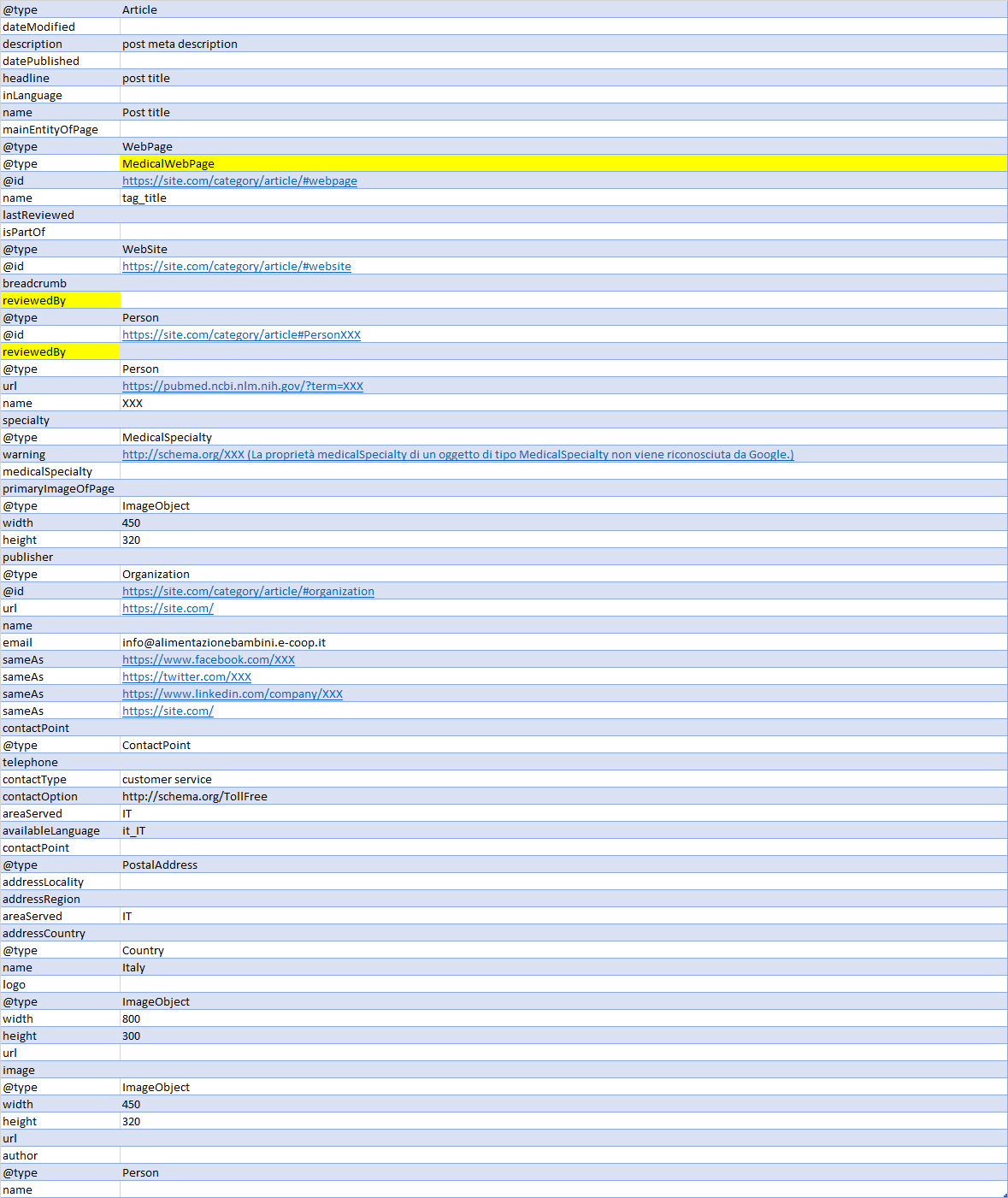
Ma veniamo al punto. Il mio obiettivo era di creare uno schema Article correlandolo tramite @id ad altri schema come Organization e MedicalWebPage che tra le properties include reviewedBy (nel mio caso Person) che a sua volta permette di specificare nome e url del revisore.
Ho fatto la cosa in 2 modi diversi (evidenziati in giallo nella tabella).- Inserendo name e url come direct text
- inserendo per il reviewer, al posto di url e name, solo la property @id relazionata (#) con uno specifico schema Person (PersonXXX nella tabella).
Mi chiedo se uno dei due metodi sia preferibile all'altro, o se addirittura inserire sia le property name e url che la @id (secondo me troppo ridondante).
A lume di naso, G e altri motori dovrebbe essere in grado di fare un fetch di dati e leggere le property relative al reviewer basandosi solo sull'@id, ma il tester di G non le mostra (mostra solo la relazione) e, come dicevo all'inizio, non trovo nessuna documentazione ufficiale che confermi la mia idea o suggerisca se preferire uno dei due modi.
Riporto di seguito una tabella relativa al mio schema article, tralasciando la sezione breadcrumb/listItem e oscurando i dati sensibili (notare che G non riconosce le varie medicalSpeciality ufficiali di schema.org).
Ogni suggerimento su come "rifinire" gli schema è bene accetto. Grazie
@alepom visto che mesi fa, dopo aver seguito il tuo bel corso sulla voice serach, ti avevo posto, sulla piattaforma, un paio di domande a cui ti sarà sfuggito rispondermi
@type Article
dateModified
description post meta description
datePublished
headline post title
inLanguage
name Post title
mainEntityOfPage
@type WebPage
@type MedicalWebPage
@id https://site.com/category/article/#webpage
name tag_title
lastReviewed
isPartOf
@type WebSite
@id https://site.com/category/article/#website
breadcrumb
reviewedBy
@type Person
@id https://site.com/category/article#PersonXXX
reviewedBy
@type Person
url https://pubmed.ncbi.nlm.nih.gov/?term=XXX
name XXX
specialty
@type MedicalSpecialty
warning http://schema.org/XXX (La proprietà medicalSpecialty di un oggetto di tipo MedicalSpecialty non viene riconosciuta da Google.)
medicalSpecialty
primaryImageOfPage
@type ImageObject
width 450
height 320
publisher
@type Organization
@id https://site.com/category/article/#organization
url https://site.com/
name
email [email protected]
sameAs https://www.facebook.com/XXX
sameAs https://twitter.com/XXX
sameAs https://www.linkedin.com/company/XXX
sameAs https://site.com/
contactPoint
@type ContactPoint
telephone
contactType customer service
contactOption http://schema.org/TollFree
areaServed IT
availableLanguage it_IT
contactPoint
@type PostalAddress
addressLocality
addressRegion
areaServed IT
addressCountry
@type Country
name Italy
logo
@type ImageObject
width 800
height 300
url
image
@type ImageObject
width 450
height 320
url
author
@type Person
name
1 Risposta
-
Mi dispiace che il copian/incolla da excel abbia prodotto questo obbrobrio forse facevo meglio a usare uno screenshot...
@alepom vedo ad esempio che tu inserisci in Author sia id@ che name, description, image e caption (io mi sarei limitato all'@id lasciando il resto, compresi eventuali sameAs nello schema Person). La per la caption fai il pull da un post meta?
C'è un motivo per cui in Organization usi sia logo che image? Così come usi sia Image che primaryImageofPage (io le avrei usate entrambe per "descrivere" 2 immagini diverse ma per la stessa ne basterebbe una sola, no?)
Avere sia Article che Blog serve? In Blog inserisci, oltre a headline e description, anche l'intero body (che comunque si potrebbe inserire in Article).
Se inserire body o meno me lo chiedo; ok che schema è per le macchine ed è utile definire di cosa trattiamo ma non dovrebbero bastare alt_title e meta description?Infine, il famigerato Speakable. Ho provato a inserirlo specificando tramite selettore CSS la parte dell'articolo "leggibile", però non mi pare che G capisca il selettore o l'xpath... O il punto è che la funzione è attiva solo in US?
-
Ciao @MaxxG,
grazie per avermi taggato nel tuo messaggio.Ti rispondo su alcuni punti.
- Grazie infinite per aver visto il mio corso sulla Voice Search. Mi fa un enorme piacere

- In merito ai messaggi che mi hai scritto e ai quali non ho risposto.. Prima di tutto mi scuso per l'inconveniente. Ho verificato sia in mail, sia su Master Club, ma non ho alcuna notifica. Quindi credo che ci sia qualche "buco di informazione" che sto già provando a capire. Ti dico anche, però, che, non vedendo risposta, avresti potuto scrivermi in uno degli "ennemila" canali in cui siamo connessi
 A me fa molto piacere. Comunque, ripeto, sto provando a capire dov'è stato il problema, e ti ringrazio per avermelo fatto presente
A me fa molto piacere. Comunque, ripeto, sto provando a capire dov'è stato il problema, e ti ringrazio per avermelo fatto presente 
- L'implementazione dei dati strutturati, come vedi dal sorgente, sul blog dove hai testato, è stata realizzata con Yoast. Io credo che se parliamo di items così semplici come quelli che possono essere presenti in un blog, andare oltre all'implementazione di questi tool nn è conveniente. Attenzione: non fraintendiamo.. non ho detto che i dati strutturati non vanno ottimizzati. A me piace moltissimo implementarli laddove vanno a dare del valore aggiunto significativo alle informazioni (non solo in ottica di rich snippet). Ma per queste entità, in una struttura come quella che hai analizzato sono più che sufficienti, considerando anche diversi aspetti (es. si tratta di un blog aziendale, l'effort di mantenimento, l'obiettivo, il fatto che essendo un CMS non c'è rischio di disallineamento di dati, ecc.).
- Detto questo, io comunque, starei attento ai nodi multi pagina. Comunque puoi fare dei test. Ad esempio, potresti creare una pagina con un certo type, e successivamente lo innesti nel Json di un'altro type con il node id. Osservando la SERP, puoi intuire se Google considera l'associazione.
Spero di averti dato qualche spunto interessante
- Grazie infinite per aver visto il mio corso sulla Voice Search. Mi fa un enorme piacere
-
Intervengo sulla discussione molto velocemente, mi manca il tempo al momento ma credo sia molto interessante.
Mi pare di capire che il tuo cruccio @MaxxG sia in estrema sintesi questo:
@maxxg ha detto in correlare schema attraverso @id:
A lume di naso, G e altri motori dovrebbe essere in grado di fare un fetch di dati e leggere le property relative al reviewer basandosi solo sull'@id, ma il tester di G non le mostra (mostra solo la relazione) e, come dicevo all'inizio, non trovo nessuna documentazione ufficiale che confermi la mia idea o suggerisca se preferire uno dei due modi.
Credo che tu sia nel giusto, anche se ti confermo che non esiste nessuna documentazione ufficiale... vediamo comunque diversi casi reali dove questo accade, uno di questi è stato citato proprio qua sul forum:
https://connect.gt/post/1283660
Qua abbiamo un caso lampante di rich snippet (recensioni) applicata alla URL articolo, anche in totale assenza di questa informazione sulla pagina... in virtù del fatto che l'articolo referenziava un'entità, entità che aveva una pagina dedicata... e le recensioni stavano su quella pagina terza.
Google ha preso questa informazione e l'ha associata all'articolo, arrivando a mostrarla come rich snippet.
Quindi abbiamo abbastanza la conferma che questo tipo di cose vengono fatte.
Riguardo al tuo cruccio specifico sulla ridondanza:
@maxxg ha detto in correlare schema attraverso @id:
Mi chiedo se uno dei due metodi sia preferibile all'altro, o se addirittura inserire sia le property name e url che la @id (secondo me troppo ridondante).
Io non me ne preoccuperei, anzi.
Considera che se sei ridondante, stai in realtà semplicemente dando dei segnali di coerenza al motore di ricerca... di fatto collegando le entità tra di loro tramite più "fili" semantici, stai semplicemente dicendo in maniera chiara che quelle entità sono correlate e sei in grado di costruire un knowledge graph più solido.
L'unico problema che vedo è che più collegamenti fai, più ti aumenta il costo di manutenzione e aumenta la probabilità di fare sviste o peggio errori di progettazione... che potrebbero portare in definitva a segnali contrastanti e a "romperti" il knowledge graph, con il risultato di non avere alcun beneficio in termini poi di rich snippet (che per me sono l'unica cosa che conta davvero, lo so sono venale
 ).
).
-
@alepom ha detto in correlare schema attraverso @id:
L'implementazione dei dati strutturati, come vedi dal sorgente, sul blog dove hai testato, è stata realizzata con Yoast
Ehm, no aborro yoast
e lavoro a manona anche perché uso property che i plugin standard non prevedono e yoast che io sappia (ma siccome lo disabilito per la parte schema potrei sbagliare) non permette alcuna customizzazione o creazione di schema diversi da quelli già implementati nel plugin.Lavoro sui nodi multipagina esattamente come indicato da te. Purtroppo in serp quello che google non "traduce" in rich snippet difficilmente puoi sapere come lo interpreta.
D'altro canto, lo strumento di test vede correttamente la pagina con il determinato type che vuoi richiamare ma non riportando tutte le property e mostrando solo la relazione non si ha certezza.
Rifarò lo stesso test su un sito con su le ricette che già producono rich snippet e vedo come aggancia Organization tanto per dire.Tra l'altro uso Wordlift ma anche loro usano un set basico di schema (salvo poi poter usare gli addon all entity e mappings agganciati ad ACF, ma parliamo del piano da 2mila l'anno!). Visto che il loro schema article di base prende come autore l'utente di wp mentre il mio schema prende un post meta scelto da me - dato che non coincide con l'utente - mi ritrovo con 2 segnali in conflitto (2 autori diversi per lo stesso articolo). Spero abbiano un hook per permettermi di impedire l'inserimento di alcune property o sospenderò il servizio e mi metterò a inserire a mano le "mention" - di fatto quello che fa wordlift - dopo aver analizzato l'articolo con un estrattore di entità (wordlift lavora al 90% con wikipedia e wikidata).
Di nuovo complimenti per il tuo corso, per una mia idiosincrasia agli assistenti mi ero lasciato indietro tutto questo mondo e il tuo corso è stato il miglio modo per iniziare sul serio a recuperare
1 Risposta
-
@alepom ha detto in correlare schema attraverso @id:
Detto questo, io comunque, starei attento ai nodi multi pagina.
Magari può interessare ad altri la risposta che mi ha dato Jason Barnard ("the brand serp guy") di kalikube (che offre un interessante servizio gratuito https://tools.kalicube.pro/add-brand) proprio a questo riguardo:
Which is the preferred method to insert the reviewers? 1) @id correlating to #PersonOne 2) Inserting url and name as direct text as sub-properties of the reviewedBy? 3) both of them (too redundant?), I mean both the @id and inserting url and name too.Good question. But I’m not quite sure (yet). I guess that Google (and maybe other search engines) can fetch data from other pages. Even if the test tool cannot show it to you. So I would say that #1 should work. However I’m not sure and there is no information about that online anywhere. So I cannot give appropriate advice here, sorry. Let me know if you find something more.
-
@kal ha detto in correlare schema attraverso @id:
Quindi abbiamo abbastanza la conferma che questo tipo di cose vengono fatte.
Hai colto nel segno i miei crucci, evidentemente mi manca il dono della sintesi, o ho la deformazione di fornire molto contesto
Ottimo a sapersi, grazie!
La ridondanza di solito non mi preoccupa, però ammetto che vedere pagine che restituiscono 4 volte il publisher ogni volta con tutta la tiritera di contactPoint ultra dettagliati, o che ripresentano tre volte le stesse informazioni come article, blogPost, CreativeWork (ne ho visti più d'uno), ecco quello mi pare solo lavorare in modo non pulito.Per fortuna che google ha capito che non doveva dismettere il tool di test sostituendolo con quello che valuta solo in funzione dei suoi rich snippet.
Cerchiamo di portarci avanti per quelli futuri
Dovessimo dar retta a Google e quello che Esso depreca... (vedi i SameAs tanto per rimanere a schema)Comunque fatte le verifiche vedrò di scrivere un howto per mostrare proprio come creare schema custom o con property custom e relazionarli fra loro (compresa una guida ai plugin visto che li ho testati TUTTI; RankMath pro, per dire, mi ha deluso visto che puoi creare from scratch ma non è mappato a schema.org quindi obbliga a ricopiare e non guida in alcun modo precaricando i subset previsti in base alle scelte precedenti, in pratica campi liberi dove è facile fare errori banali; per lo meno implementa un debugger).
-
@maxxg ha detto in correlare schema attraverso @id:
e yoast che io sappia (ma siccome lo disabilito per la parte schema potrei sbagliare) non permette alcuna customizzazione o creazione di schema diversi da quelli già implementati nel plugin.
Yoast è terribile per i dati strutturati! Customizzare è impossibile: o ti tieni quello che ti propina lui, oppure meglio cambiare proprio plugin.
-
@kal ha detto in correlare schema attraverso @id:
ho osservato un po' questo caso e mi chiedo: se non ci fosse un link in pagina verso la pagina tag che contiene la review (relazione riportata ovviamente nello schema breadcrumb) e ci fosse solamente la correlazione via schema Article, aggiungendo alle sub-property di aggregateRating anche un @id con l'url della pagina tag con la recensione, Google sarebbe comunque in grado di produrre il rich snippet? Peccato non poter testare.
Peraltro la pagina tag a livello di schema è un disastro perché anche se ha il rating in frontend poi non ha la property corrispondente nello schema VideoGame
-
@maxxg sì, quel caso è tutto tranne che ben organizzato, hanno un disastro nel knowledge Graph, manco mi son messo a fare reverse engineering

Chissà quale è la logica che ha portato Google a mettere la rich snippet a quel modo!