- Home
- Categorie
- Digital Marketing
- SEO
- Nuovo report Crawl Stats in Google Search Console
-
L'unico problema di questo strumento è che mostra i dati in ritardo di 3 giorni e nell'analisi log non averli in realtime lo rende molto meno utile di quanto potrebbe essere.
Di conseguenza non potrà sostituire mai uno strumento di analisi log.
1 Risposta
-
Questo post è eliminato!
1 Risposta
-
@juanin aspetta però, forse può sembrare banale come domanda, ma nei 286.601 per quali bot hai filtrato?
Esattamente per le tipologie indicate in tabella?
Es. per un mio sito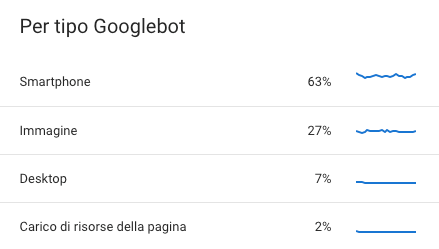
Che poi la somma di queste percentuali fa 99% non 100%.
In questi giorni verificherò anche io la corrispondenza tra LOG e dati in Search Console per un determinato giorno
1 Risposta
-
@filipposogus no spe mi sono accorto ora che ero finito in un filtro....
Il dato torna! Mea Culpa

Elimino il post per non fuorviare nessuno.
-
@juanin ha detto in Nuovo report Crawl Stats in Google Search Console:
L'unico problema di questo strumento è che mostra i dati in ritardo di 3 giorni e nell'analisi log non averli in realtime lo rende molto meno utile di quanto potrebbe essere.
Di conseguenza non potrà sostituire mai uno strumento di analisi log.
Direi anche io che non possa sostituire, però è comunque tanta roba, ci si avvicina moltissimo.
Ti permette di vedere a colpo d'occhio tante cose che fino ad ora vedevi solo nei log, ad 1/100 del costo "logistico" per avere i log che come tutti sappiamo è enorme e anche la loro elaborazione/pruning non è una cosa che fai in 3 secondi.
Inoltre, abilita all'analisi avanzata anche tutti quei siti che per motivi vari non hanno proprio accesso ai log.
-
@kal no ci mancherebbe. E' SUPER, ma non copre diciamo tutti i casi d'uso. Per quei casi d'uso caccia la grana!

-
Aggiungo, hanno descritto meglio la metrica del tempo medio di risposta della pagina...
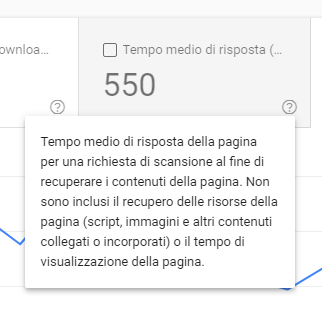
Ma a me continua a non tornare.
Quella metrica NON è il TTFB.
Per capirci, se lo stesso sito dell'immagine sopra lo testo con PageSpeed:
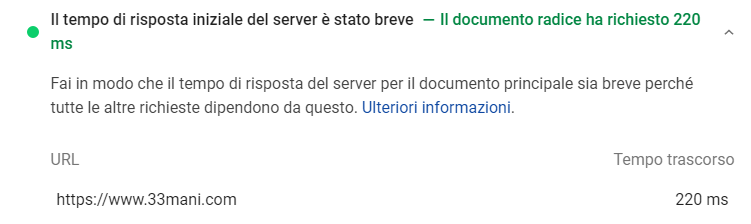
E peraltro il TTFB di Pagespeed è anche quello medio che risulta a me se faccio una scansione a tutto tondo.
Mi restano quindi fuori 300ms buoni che non si capisce cosa sono.
Mi sbaglierò, ma per me la metrica di GSC include il download del sorgente HTML.
-
@kal avevo fatto una domanda anni fa in merito a Mueller che mai rispose.
Si quel tempo è il Download Time e non il Response Time con altissima probabilità. Ho il sospetto da anni.
Infatti io ho già fatto dei test riducendo pesantemente il DOM della pagina HTML e ho ottenuto ottimi risultati.
-
@juanin avrebbe anche senso da un punto di vista del SEO tecnico... perché di fatto quello è il tempo in cui il crawler è "occupato", dall'invio della richiesta fino alla chiusura del payload della stessa.
Vabbè, io continuerò ad interpretarlo a quel modo, checché ne dica GSC.
-
@kal eccolo qua...recuperato https://twitter.com/SEOForBabies/status/1040606996091883520
Comunque si il valore più vicino a quello che mostra lì è il download time. Non il TTFB.
Che poi te lo posso confermare anche dalle differenze che vedo tra i response time nei log e quelli in GSC:
- LOG -> 149ms (response time)
- GSC -> 271ms (download time)
Prendiamo i dati utente (che ovviamente hanno response molto più rapida per questioni geografiche e di cache hit ratio:
- Analytics -> 0.05 (download time)
- Analytics -> 0.22 (response time)
Sono delle average ovviamente quindi da prendere con le pinze perché dipende molto dal tipo di pagine, ma se facciamo 0.22 + 0.05 abbiamo 0.27 che torna molto con il valore di GSC.
-
@juanin ha detto in Nuovo report Crawl Stats in Google Search Console:
@kal eccolo qua...recuperato https://twitter.com/SEOForBabies/status/1040606996091883520
Sì, ricordo anche io molto bene quel thread! Peccato che non abbia chiarito. E anche la descrizione che troviamo ora nel report è confusa.
Dice "al fine di recuperare i contenuti della pagina" e anche "non include il tempo di visualizzazione della pagina".
Sembrerebbe quindi che si limiti al Download Time (recuperare i contenuti) della sola risorsa scansionata e non anche delle risorse in essa collegate (necessari per la "visualizzazione", ovvero il rendering).
Però è un arrampicamento sugli specchi fatto per allineare quella metrica con la nostra esperienza... ma rimane poco chiaro.
-
@kal ho aggiornato il commento sopra cercando di fare una comparazione tra i vari strumenti a disposizione.
-
@juanin Ho fatto anche io un controllino su GA.
Ed in effetti:
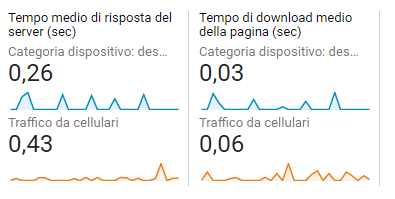
Su cellulare ho un tempo di risposta medio di 0,43 + un tempo di download medio di 0,06 = 0,49
Praticamente identico a GSC dove ormai ho richieste perlopiù da Googlebot Mobile.
-
@kal sei lentino allora
datti da fare. Pulisci quel DOM. Ho ottenuto buoni risultati. Se non lo usi ancora spara un bel brotli.
-
@juanin non sono io lentino, sei te che sei un professionista su sta roba! Oggettivamente non ci ho dedicato molto tempo HAHAHA sull'aspetto della web performance mi son sempre "accontentato" per i miei progetti.
Inoltre non ho gran modo di intervenire sul server, con il mio 33mani sto su uno shared. Uno shared buono (Level 19 di Hetzner), con SSH e qualche funzioncina di configurazione decente (ho brotli! Farò un test...), ma comunque uno shared.
Anche perché in realtà i CWV stanno "apposto, tutti verdi", quindi come si suol dire mi sono accomodato bellamente sugli allori.
Ma mi fermo qui sennò andiamo OT.
-
Lo aspettato da molto tempo. Ora speriamo finiscano anche gli altri strumenti che sono ancora nella vecchia GSC.
-
@andreamelloni stavo guardando con interesse come in molti siti la quota di "Other file type" sia altissima.
Guardando su un sito come Nencini (sufficientemente certo non ci siano problemi di server o file type) la lista è davvero strana:
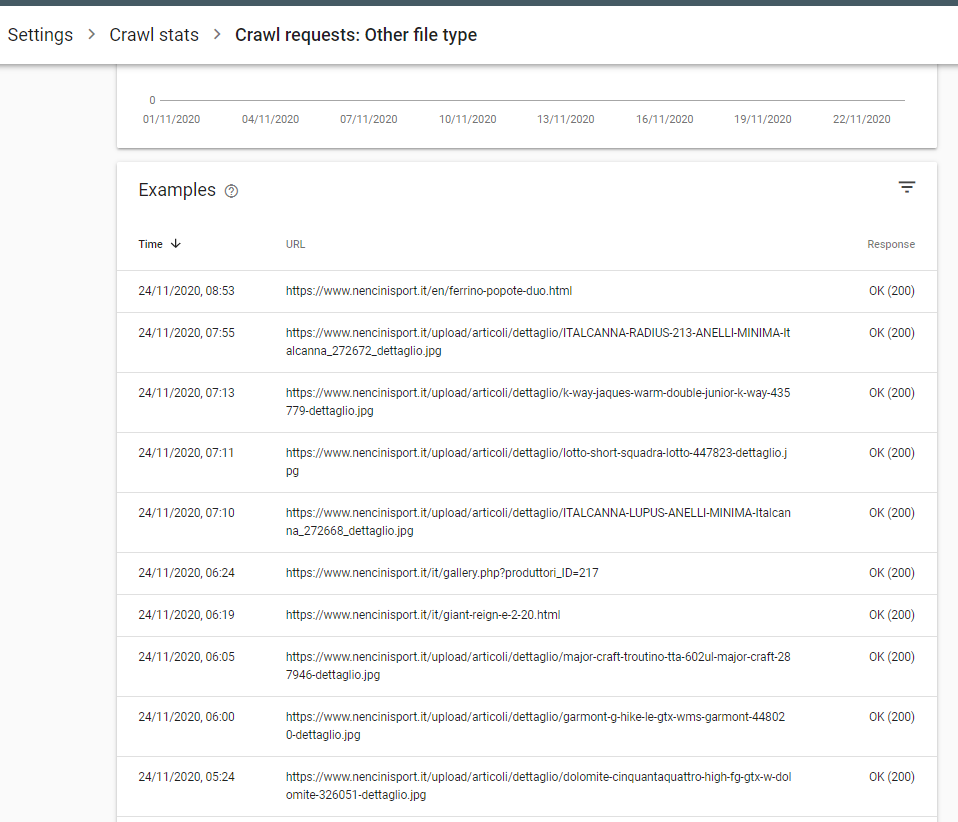
Poi però andando ad analizzare la prima pagina c'è una nota ancora più strana:
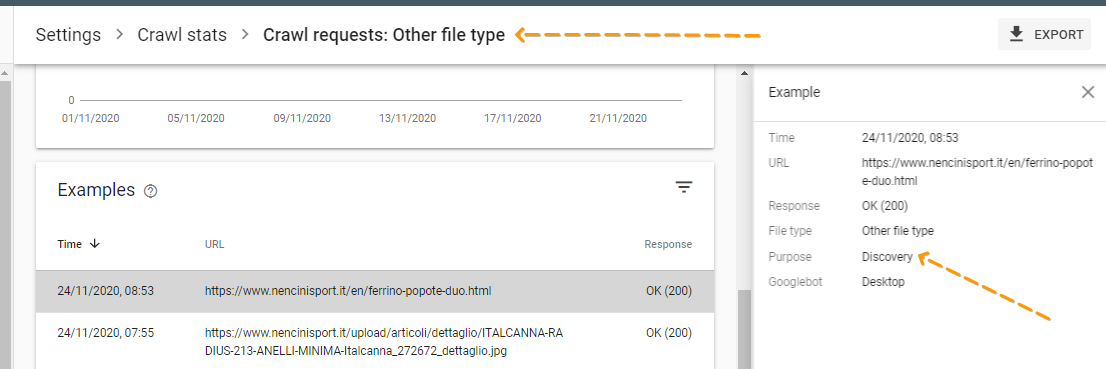
Purpose: Discovery
Che è quel "purpose"? Nel caso di altri file tipo immagini mi mette "refresh".
Sembra stia ad indicare se quella risorsa la sta aggiungendo "discovery" o aggiornando "refresh".
-
@merlinox ha detto in Nuovo report Crawl Stats in Google Search Console:
stavo guardando con interesse come in molti siti la quota di "Other file type" sia altissima.
Guardando su un sito come Nencini (sufficientemente certo non ci siano problemi di server o file type) la lista è davvero strana:Ti confermo che è strana! In un caso almeno in quella lista ci ho beccato la homepage... molto perplesso

Mia ipotesi campata in aria: sono crawl request che Google considera andate a buon fine ma magari sono troncate? Per qualche problema di rete o altro... oppure per qualche ragione è Googlebot che non ha salvato il file type.
Questa cosa spiegherebbe anche perché hanno nascosto quella voce in fondo alla lista, anche se spesso è bella corposa.
1 Risposta
-
Io ho trovato un caso dove altro tipo di file è 100%, ma poi in nessuna delle mie property vedo la lista di URL di esempio.
-
Ho notato che quella percentuale se sommo i 301 e i 304 corrisponde.
Quindi altro tipo di file secondo me sono quelli perché di fatto non c'è un body di risposta o un content type. Ha senso.