@mirkomassarutto hai ragione sono di meno, il numero preciso dovrebbe avvicinarsi più ai 5 mln che ai 6.
Grazie del tuo augurio e buona serata!
@mirkomassarutto hai ragione sono di meno, il numero preciso dovrebbe avvicinarsi più ai 5 mln che ai 6.
Grazie del tuo augurio e buona serata!
Ciao a tutti!
Grazie di tutte le indicazioni e scusate del ritardo del riscontro.
@kal ti ringrazio delle info. Mi era abbastanza chiaro il processo scansionamento / crawling e indicizzazione, ma onestamente non mi ero mai posto il problema di che cosa sarebbe successo se avessi bloccato lo scansionamento di una pagina indicizzata.
Anche perché oggettivamente fino ad adesso il mio problema era sempre stato indicizzare le pagine.
Articoli di Andrea Scarpetta, mi è capitato l'ultimo nel feed di LinkedIn e l'ho girato lunedì al reparto tecnico, anche perché usiamo proprio Cloudflare.
@sermatica grazie delle indicazioni. Dall'analisi che hanno fatto i colleghi del reparto tecnico sono principalmente Googlebot e Bingbot. Confermo che mi ritrovo le scansioni in Google Search tutti i giorni, Webmaster Tool di Bing confesso che non l'ho consultato. Il traffico generato da quelle tipologie di pagine è risibile.
@mirkomassarutto purtroppo non è completamente assurdo.
Come indicato anche precedentemente visto che il sito aveva dei gravi rallentamenti che influivano chiaramente su tutte le pagine e quindi sulle conversioni, determinato, secondo il reparto tecnico, in gran parte dalla richiesta dei bot di quelle 12 mln di pagine che erano funzionali al sito, ma avevano in parte contenuto duplicato e non stavano né generando traffico organico né conversioni.
Quindi per me non è stato completamente assurdo rinunciare a quelle pagine pur di salvare l'usabilità e lavorare ad altre 6 mln di pagine e migliorare le conversioni.
Anche se non credo che mi abbiano dato informazioni errate ho comunque richiesto al reparto tecnico di esportarmi i dati dei log e domani verificherò direttamente io con SEO Log File Analyser di Screming Frog le reali percentuali di richieste dai diversi Bot e successivamente capirò con loro se possiamo in qualche modo salvare quelle pagine (ad esempio se è sufficiente bloccare quegli spam con le indicazioni di Andrea Scarpetta) o bisogna intervenire con il disallow nel robots.txt.
Grazie mille a tutti della disponibilità e buona serata!
@kal ti ringrazio e completamente d'accordo sulla correttezza del mondo ideale ed onestamente mi trovo anche in una situazione paradossale nel "non" dover far indicizzare delle risorse ma purtroppo in questo caso siamo davanti a 6 mln di pagine x 3 e quindi ad una quantità di risorse enorme.
Abbiamo sottovalutato la possibile problematica ma lasciando la situazione così rischiamo di generare un rallentamento del sito e una cattiva esperienza degli utenti.
Bloccandole con Disallow tramite Robots.txt non sarebbero lo stesso scansionate dal bot perché linkate dalla pagina scheda azienda?
"While Google won't crawl or index the content blocked by a robots.txt file, we might still find and index a disallowed URL if it is linked from other places on the web."
https://developers.google.com/search/docs/crawling-indexing/robots/intro
Grazie mille dell'aiuto e delle indicazioni
@sermatica utilizziamo Google Cloud, la pagina viene "cachata" ogni volta che viene visitata da utenti o bot.
Il problema è la quantità di richieste che avviene contemporaneamente che genera un sensibile rallentamento del sito.
E' per questo che vorremmo bloccare la scansione (non semplicemente l'indicizzazione) di quella tipologia di pagine che producono in parte l'eccesso di richiesta e di cui non ci interessa l'indicizzazione.
Non posso eliminarle perché sono funzionali al sito.
@kal , prima di tutto complimenti per il test presentato al SEO Advanced Tool.
Il problema è che, come dicevo prima, quelle pagine sono funzionali al sito, si può acquistare un prodotto e quindi non posso né rimuoverle né accorparle.
Sono pagine raggiungibili:
In pratica il mio problema è se c'è un modo per impedire ai Bot (Googlebot o altri) di eseguire la scansione tramite i link presenti nella pagina scheda azienda?
Il nofollow a livello di pagine scheda azienda (o sul singolo link) + noindex a livello di X-Robots tag nelle pagine prodotto + azienda potrebbe essere la soluzione?
Ciao Mirko, ti ringrazio del riscontro.
Si confermo l'obiettivo è bloccare le richieste delle risorse tipologia di pagine "prodotto + azienda" da parte di qualsiasi bot, incluso Googlebot.
Il sito è di grandi dimensioni con centinaia di migliaia di url.
C'è una scheda azienda che linka ad altre pagine con prodotti associati all'azienda.
Questo tipo di struttura genera migliaia di pagine e rispettive richieste.
Per come è fatto il sito non possono essere accorpate le due diverse tipologie di pagine.
L'obiettivo è ridurre / bloccare le richieste delle risorse sulle pagine prodotto + azienda per efficientare il numero di richieste viste le dimensioni del sito.
Attualmente quelle pagine (azienda + prodotti) in search console sono nel seguente stato:
Il programmatore le sta bloccando per i picchi di traffico.
Quale potrebbe essere la soluzione per bloccare non solo l'indicizzazione delle pagine prodotto + azienda ma anche la scansione / richiesta senza restituire uno stato 403 che immagino non sia il massimo anche in virtù del numero di pagine?
Io ho pensato a:
1) Robots.txt
Bloccherebbe la scansione e quindi l'indicizzazione ma non funzionerebbe perché quelle risorse sono comunque linkate dalla pagina interna scheda azienda
2) Meta noindex
Nell'head delle singole pagine prodotto + azienda riuscirebbe a far non indicizzare le pagine, ma teoricamente non bloccherebbe lo scansionamento / richiesta.
3) Nofollow
Potrebbe essere il nofollow a livello di pagina che linka alle pagine azienda + prodotto o su singolo link interno la soluzione?
<meta name="robots" content="nofollow">
Magari associato alla 2° soluzione (meta noindex sulla pagina azienda + prodotto)?
Il nofollow per i link interni potrebbe ridurre anche lo scansionamento della pagina linkata? Googlebot potrebbe smettere di effettuare il crawling di pagine linkate solo da link nofollow?
Grazie a chiunque potrà darmi dei suggerimenti!
Salve Daniele,
prima di tutto ti ringrazio del tuo contributo.
Provato ma purtroppo non è sufficiente perché Screaming Frog Log File Analyzer mi consente di analizzare i log ma non di confrontarli con i dati provenienti dal database.
Io invece avrei bisogno di matchare url del database (data di inserimento) con quelli del log (quando per la prima volta quell'url viene richiesta da Googlebot o Bingbot) così da poter verificare i tempi di crawling delle risorse di nuova pubblicazione
Grazie ancora e buona serata!
Ciao a tutti,
vorrei analizzare i tempi che googlebot e bing bot impiegano a indicizzare contenuti a partire dalla loro pubblicazione.
Ho preso in considerazione 7 giorno.
Estratto dal database le url e le data di pubblicazione e scaricato i log del server nello stesso arco di tempo.
Il mio problema è che il sito genera centinaia di pagine quotidianamente e migliaia di events sui log da parte dei bot.
Ho provato anche a filtrare i log per bot (google, bing) e ridurre ad un giorno ma il numero di url da confrontare resta ancora poco gestibile per strumenti come google sheet o excel
Voi usate strumenti particolari per fare analisi simili?
Salve Sermatica!
Purtroppo non c'è nessuna risorsa bloccata tramite Robots.txt.
Ho richiesto un consiglio ad un SEO molto più esperto di me e mi ha indicato che in caso di "Other Error" in Search Console > test in tempo reale url potrebbe essere determinato dal fatto che si sta superando la quota disponibile per il Fetch per cui Google interrompe in modo proattivo la richiesta, senza contattare il server.
Qui c'è un riferimento ad un thread sulla community search console in cui vengono date alcune indicazioni al riguardo.
Grazie mille comunque del tuo aiuto.
Salve a tutti!
Stavo verificando il mio sito con Controllo URL > Test in Tempo Reale ed in "Ulteriori informazioni" mi ritrovo molte risorse che mi segnala come "Impossibile Caricare" (27 risorse su 67 di tipo JPG, PNG, JS)
Le risorse però sono tutte raggiungibili
Lo screenshot della pagina non si visualizza correttamente
Provando a testare con il sistemista durante il test in tempo reale la richiesta delle risorse (impossibili da caricare) sembra non arrivare proprio al server
Le performance analizzate con Lighthouse sembrano essere buone / molto buone: Performance 89 / Accessibility 100 / Best Practice 80 / SEO 100
Quindi sembra non esserci problemi di caricamento pagine in generale.
Avreste qualche suggerimento per risolvere il problema di caricamento di quelle singole risorse?
Grazie mille in anticipo!
Alessandro
Ciao Matteo,
prima di tutto ti ringrazio della tua risposta ed è un piacere interloquire con te perché ti leggo spesso e ti seguo con piacere.
Non posso approfittare purtroppo  del tuo template perché noi non abbiamo una thank you page ed inviamo l'hit della transazione lato server
del tuo template perché noi non abbiamo una thank you page ed inviamo l'hit della transazione lato server
Ecco il nostro codice che sembrerebbe corrispondere a quello della documentazione Google che hai condiviso:
{
"client_id":"cid",
"events":[{
"name":"purchase",
"params":{
"currency":"EUR",
"items" :[{
"item_id":"Codice Prodotto",
"item_name":"nomeprodotto",
"price":prezzoprodotto
}],
"transaction_id":"idprodotto",
"shipping":0,
"value":prezzo totale transazione,
"tax":importo tassa
}
}]
}
2 e 3 - Inseriti, giuro su Avinash Kaushik
4. Hit builder si, si testato ed in parte i dati che vedrai sono stati generati da quello
I miei dubbi sono
1 - Quantità
Nella documentazione ufficiale negli "Item Parameters" non si fa mai riferimento al parametro quantità. Posso inserirlo senza problemi? Hai già provato?
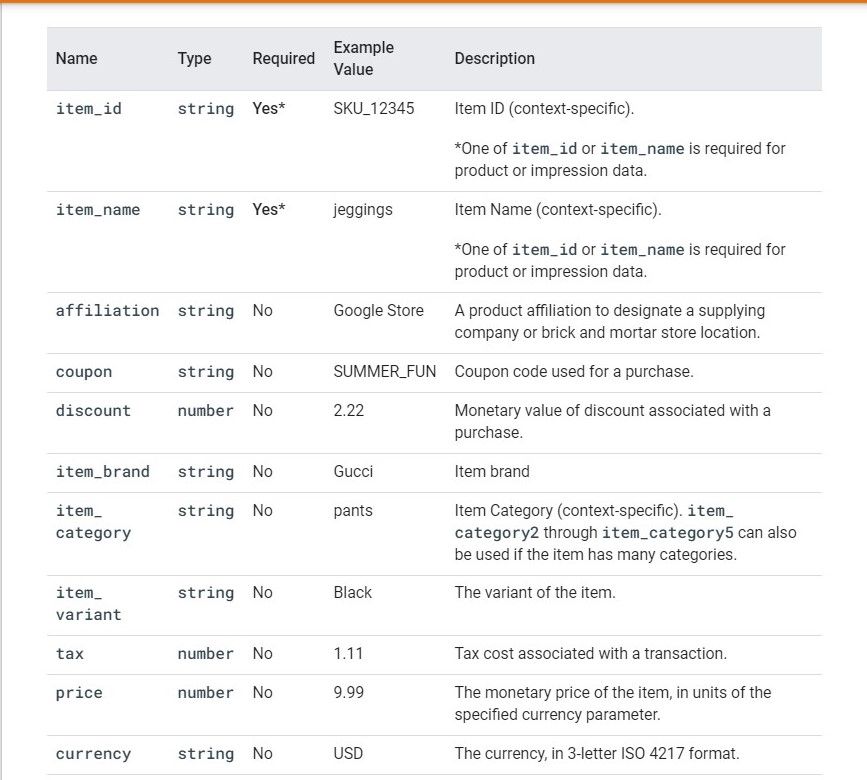
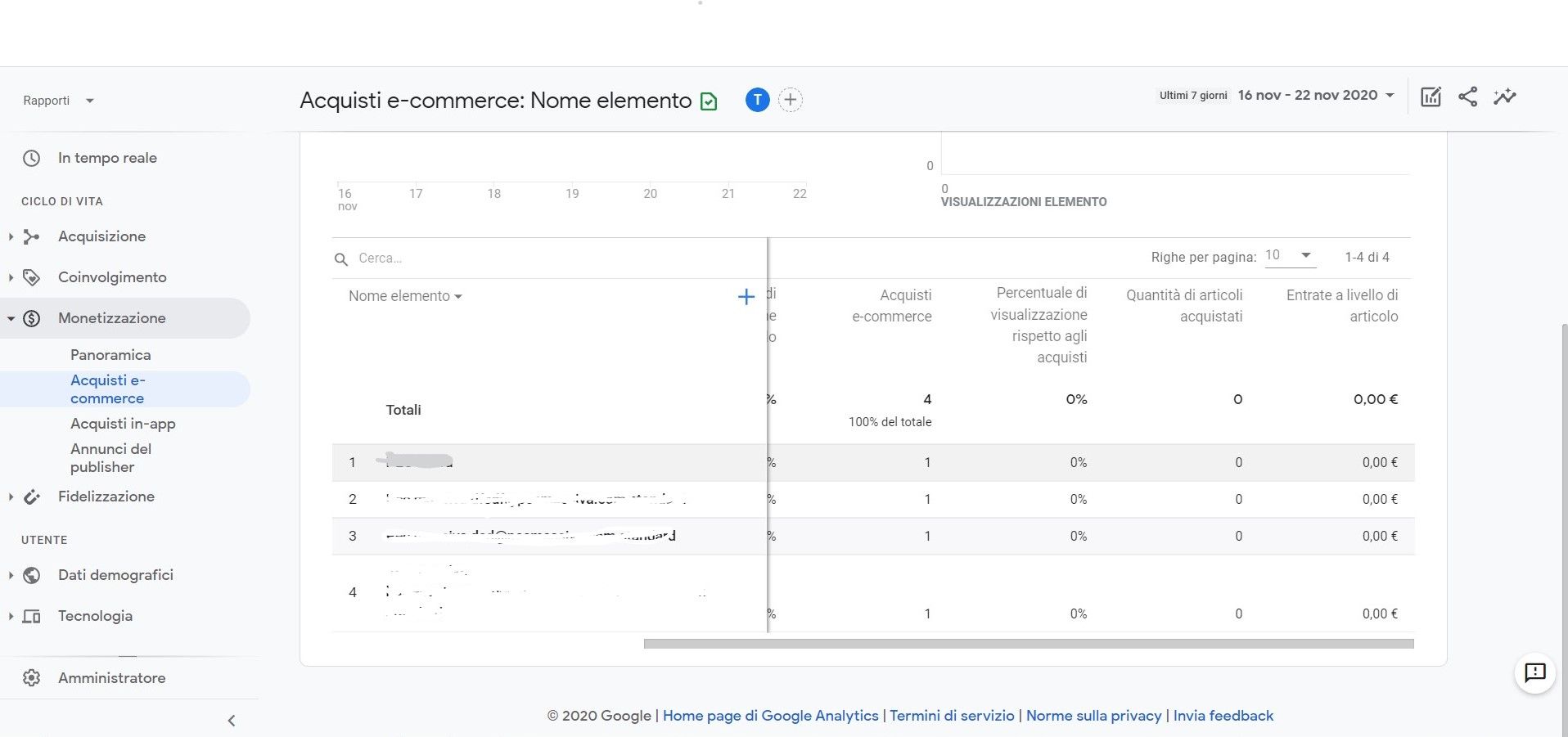
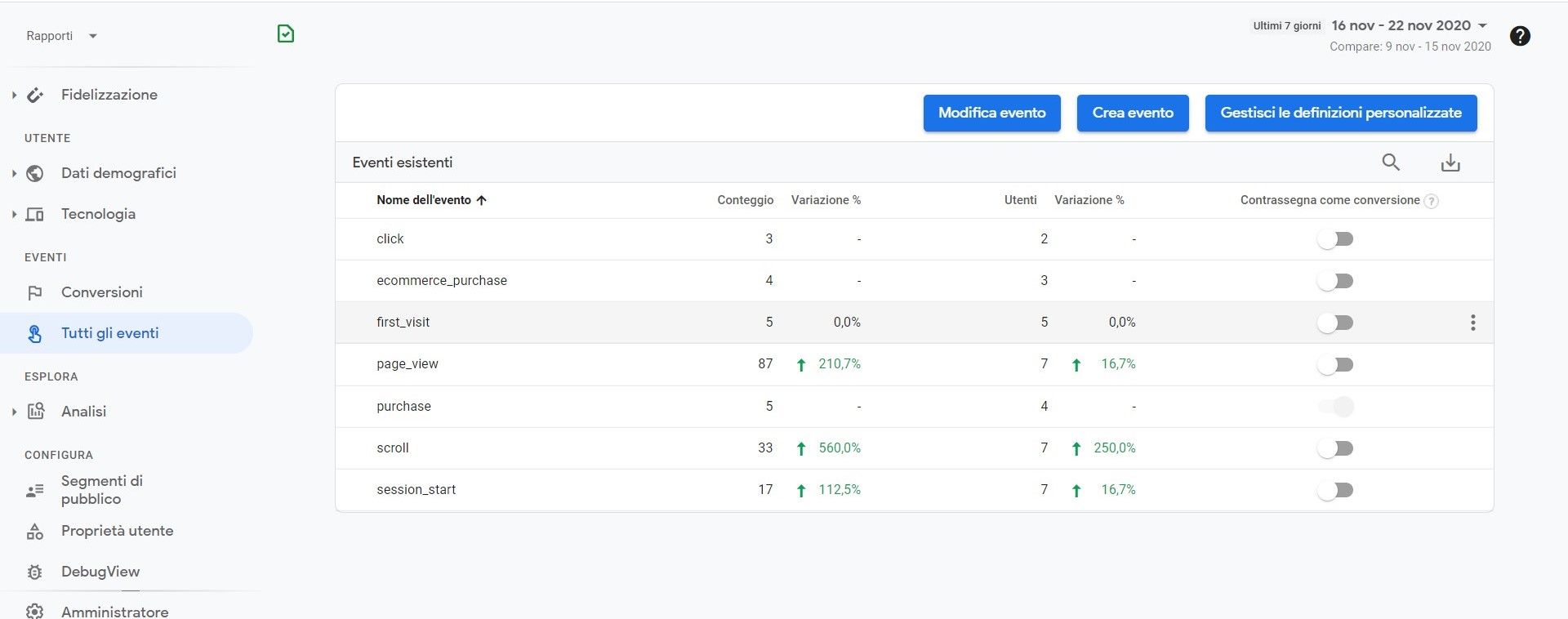
Grazie mille
Ciao a tutti!
Ieri con il collega dell'area sviluppo abbiamo provato ad implementare il measurement protocol per tracciare le transazioni per #GA4. Nuovo account obbligati di default ad utilizzarlo.
Abbiamo seguito la documentazione ufficiale dedicata all'evento "purchase" (https://developers.google.com/analytics/devguides/collection/protocol/ga4/reference/events#purchase)
Abbiamo notato 2 cose:
Abbiamo poi utilizzato come nome evento "ecommerce_purchase" (deprecato) che però a livello di:
Qualcuno di voi ha già implementato l'evento purchase e riscontrato e risolto la stessa problematica?
Grazie mille e buona giornata!
Grazie mille Martino-
Buona giornata e buon lavoro!
Alessandro
Ciao a tutti!
Attualmente tracciamo gli acquisti tramite Measurement Protocol perché l'e-commerce non ha una thank you page e abbiamo un nostro gateway di pagamento.
Vorrei passare dall'e-commerce standard all'e-commerce avanzato per monitorare anche i rimborsi.
Ho letto la documentazione ufficiale di Google riguardante il protocollo di misurazione in particolare le transazioni per l'e-commerce avanzato e afferma che "I parametri dell'e-commerce avanzato devono essere inviati con un hit esistente (ad es. Pageview, evento)"
Come indicato non ho una pagina di ringraziamento, per il parametro page (dp ") potrei passare come valore anche un url inesistente?
potrei passare come valore anche un url inesistente?
E se sì, potrei anche usarlo come obiettivo per definire il funnel di check-out?
Grazie mille!
Buongiorno Federico,
grazie del tuo aiuto e della spiegazione tecnica ed esauriente (si è stato implementato un redirect 307 e verifico se è stata impostata una lingua dove reindirizzare i bot). Tra l'altro è un piacere comunicare direttamente con te dopo averti ascoltato in diversi eventi.
Assodato che l'accept-language forse non è stata una scelta ottimale, oltre ad implementare l'href lang per pagine corrispondenti nelle altre lingue, ci sono ulteriori attività che potrei implementare per consentire ai bot di trovare gli altri percorsi nelle altre lingue?
Ad esempio se in search console aggiungo la proprietà example.com (la homepage dove avviene il reindirizzamento) e aggiungo un indice di sitemap in cui sono inseriti i riferimenti alle sitemap nelle diverse lingue potrebbe aiutare?
Grazie mille e buona giornata
Alessandro
Ciao a tutti! SOS. Sito multilingua con reindirizzamento automatico basato sull'Accept-Language. Ho letto delle potenziali difficoltà che il bot di Google potrebbe avere nell'indicizzare le risorse nella versione non americana del sito. Aggiungendo in search console tante proprietà per ciascuna lingua (es. example.com / it), impostando la lingua, aggiungendo le sitemap per ciascuna lingua e href lang potrei risolvere questa criticità? E se no, ci sono altre attività che potrebbero aiutare? Grazie a tutti!
Ciao Juanin,
ti ringrazio della risposta, approfitto della tua disponibilità per un ulteriore suggerimento.
Nella sitemap delle immagini con url, tu quale url dell'immagine inseristi a questo punto quelle rinominate dal pagespeed o le altre?
Grazie mille e buona serata
Alessandro
Ciao a tutti!
Riprendo una questione aperta tempo fa sul REWRITE_IMAGES di PageSpeed.
Sto lavorando ad un ecommerce dove se clicchi sull'immagine del prodotto, puoi vedere l'immagine ingrandita e dove è stato installato il pagespeed.
Sulla pagina prodotto mi ritrovo con un tag <img> con l'url dell'immagine rinominata da pagespeed e, visto l'effetto zoom, con l'href alla risorsa immagine su cui avevo lavorato con naming più attento su un url diverso
In pratica la situazione è simile a questa:
<img src="/image/xscarpe-da-ginastica.jpg.pagespeed.ic.IJdTup1kHV.webp" alt="Scarpe da running" title="Scarpe da running" class="" data-pagespeed-url-hash="3215672668" onload="pagespeed.CriticalImages.checkImageForCriticality(this);">
<a title="Scarpe da running" href="/image/scarpe-da-ginastica.jpg" class="popup-img overlay"></a>
Ho notato anche che in google image l'immagine indicizzata è quella rinominata dal pagespeed.
Mi trovo davanti ad una situazione di contenuti duplicati o in questo caso Googlebot Images è in grado di "canonicalizzare" automaticamente una delle due immagini?
Grazie mille
Alessandro
Ciao a tutti, ho letto diverse discussioni e articoli, vi chiedo gentilmente alcuni chiarimenti.
Quando si è in presenza di un ecommerce con prodotti non più presenti e che comunque sono state indicizzati da google e hanno raggiunto dei posizionamenti interessanti nelle SERP:
E' corretta come procedura?
Grazie mille e buona giornata
Alessandro
Dominio:
esempio
Motori:
Google
Prima indicizzazione o attività:
2010
Cambiamenti effettuati:
no
Eventi legati ai link:
no
Sito realizzato con:
CMS proprietario
Come ho aumentato la popolarità:
no
Chiavi:
no
Sitemaps:
Si
Ciao a tutti,
qualche giorno fa ho modificato il file .htaccess inserendo questo codice per bloccare il bot spam buttons-for-website:
RewriteEngine on
RewriteCond %{HTTP_REFERER} ^http ://. buttons\ -for -website.com/
RewriteRule ^(.)$ – [F,L]
La modifica mi ha provocato un errore 500.
Ho quindi eliminato il file .htaccess e l'ho ricreato all'interno del plugin Yoast in WordPress e parzialmente risolto il problema inserendo solo il codice che segue:
<IfModule mod_rewrite.c>
RewriteEngine On
RewriteCond %{HTTP_REFERER} ^http:/ / .buttons -for-website\ .com/
RewriteRule ^(.)$ - [F,L]
RewriteBase /
RewriteRule ^index.php$ -
RewriteCond %{REQUEST_FILENAME} !-f
RewriteCond %{REQUEST_FILENAME} !-d
RewriteRule . /index.php
</IfModule>
Il problema è che se solo provo a ripristinare la situazione precedente all'errore inserendo questo codice:
<files wp-config.php>order allow, deny deny from all</files>
injectionOptions +FollowSymLinks
RewriteEngine
OnRewriteCond %{QUERY_STRING} (<|%3C).script.(>|%3E) [NC,OR]
RewriteCond %{QUERY_STRING} GLOBALS(=|[|%[0-9A-Z]{0,2})
RewriteCond %{QUERY_STRING} _REQUEST(=|[|%[0-9A-Z]{0,2})
RewriteRule ^(.*)$ index.php [F,L]
<IfModule mod_rewrite.c>
RewriteEngine On
RewriteBase /
RewriteRule ^index.php$ -
RewriteCond %{REQUEST_FILENAME} !-f
RewriteCond %{REQUEST_FILENAME} !-d
RewriteRule . /index.php
</IfModule>
o ad aggiungere ulteriori blocchi a bot spam
RewriteEngine On
RewriteCond %{HTTP_REFERER} ^ http: //. *buttons -for-website\ .com/ [NC,OR]
RewriteCond %{HTTP_REFERER} ^ Http: // .*ilovevitaly. ru / [NC,OR]
RewriteCond %{HTTP_REFERER} ^ Http: // .*ilovevitaly .org/ [NC,OR]
RewriteCond %{HTTP_REFERER} ^ Http: // . *ilovevitaly .info/ [NC,OR]
RewriteCond %{HTTP_REFERER} ^ Http : //.*iloveitaly .ru/ [NC,OR]
RewriteCond %{HTTP_REFERER} ^ Http : //. *ilovevitaly .com/ [NC,OR]
RewriteCond %{HTTP_REFERER} ^ Http :// .darodar .com/
RewriteRule ^(.)$ - [F,L]
si ricrea il problema.
Qualcuno sa come risolvere la questione.
Grazie mille