- Home
- Categorie
- Digital Marketing
- SEO
- Esportare dati dai webmaster tools
-
I redirect non mi preoccupano, sono li dal passio del sito da http a https fatto 4/5 anni fa oramai
Ai noindex ci arriva perchè noi li linkiamo dall'interno delle pagine ma non ci interessa che google le indicizzi
Mentre i canonical li utilizziamo solo per gli elenchi paginati (es. se abbiamo page=0, page=1 . . . ) mettiamo il canonicalMi preoccupano le Discovered - currently not indexed che sono 800.000
Il sito è fatto custom non utilizziamo cms e non ci sono pagine generate
questi alcuni esempi delle pagine non ancora indicizzate (il sospetto che mi viene è che sia fatta male la link interna)
-
la cosa mi preoccupa anche perchè su un'altro nostro sito (l'omologo inglese) stiamo avendo un calo delle url indicizzate e non capiamo come mai https://connect.gt/topic/244321/url-deindicizzate-da-google?_=1609080836737
-
Discovered - currently not indexed così alte = 100% un problema di crawl budget.
Probabile che buona parte di quelle URL siano spazzatura, ma a occhio avete un grosso problema, perche così anche il buono viene indicizzato a fatica.
C'è un po' di lavoro da fare mi sa

Comunque non ti serve esportarle tutte. Devi capire in che condizioni si generano le URL problematiche e risolvere alla fonte, ovvero:
-
Evitare che si generino in prima battuta
-
Redirigerle con 301 alla versione canonica o in alternativa farle andare (serenamente) in 404
-
-
e come si può aumentare il crawl budget, mi sembra già discreto e come potremmo aumentarlo ulteriormente?
Non riesco a capire su quali lavori ci dobbiamo orientare
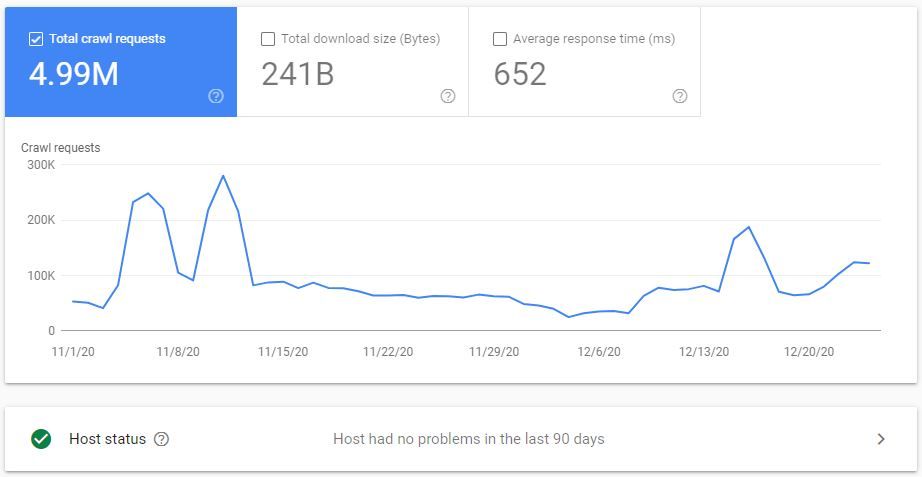
1 Risposta
-
@bonzer1 ha detto in Esportare dati dai webmaster tools:
e come si può aumentare il crawl budget
Non devi "aumentarlo". Devi gestirlo meglio.
Con il budget assegnato, devi fare sì che Google scansioni SOLO pagine buone ed eviti di scansionare pagine fuffa.
-
Ciao @bonzer1 ,
Concordo con @kal , hai definitivamente un problema di crawl budget.Non c'è un modo immediato per aumentarlo, lo assegna il motore di ricerca.
Per farti capire in termini pratici il problema, prendi per esempio tutti gli URL inutili (redirect, noindex, e URL non canonici); sono circa una milionata.
Se anche la frequenza di scansione fosse impostata al massimo (come è probabile già sia) di due richieste al secondo, conti alla mano solo per scansionarli ci vogliono almeno sei giorni. Sei giorni (probabilmente molti di più) dedicati a scansionare URL inutili a scapito degli altri.Aumentare la frequenza di scansione - se non è già al massimo - non risolverebbe il problema di crawl budget.
Non ti consiglio di cambiarla, ma puoi andare a vedere come è impostata dagli strumenti legacy di GSC.Gli strumenti per risolvere?
Correggere i link che portano a redirect, escludere dai percorsi di esplorazione tramite attributo rel="nofollow" e/o regole Disallow nel file robots.txt, e proponendo ove possibile solo il link all'URL canonico.Spero d'esserti stato utile.
1 Risposta
-
Perché hai delle url che mandano ai noindex?
Se ti servono per gli utenti prova eventualmente a togliere l'href ed utilizza js per arrivarci
-
@federico-sasso
Grazie per la risposta, uno dei problemi potrebbe essere che gran parte del crawl budget viene disperso per scansionare risorse tipo il server con le immagini, le api . . .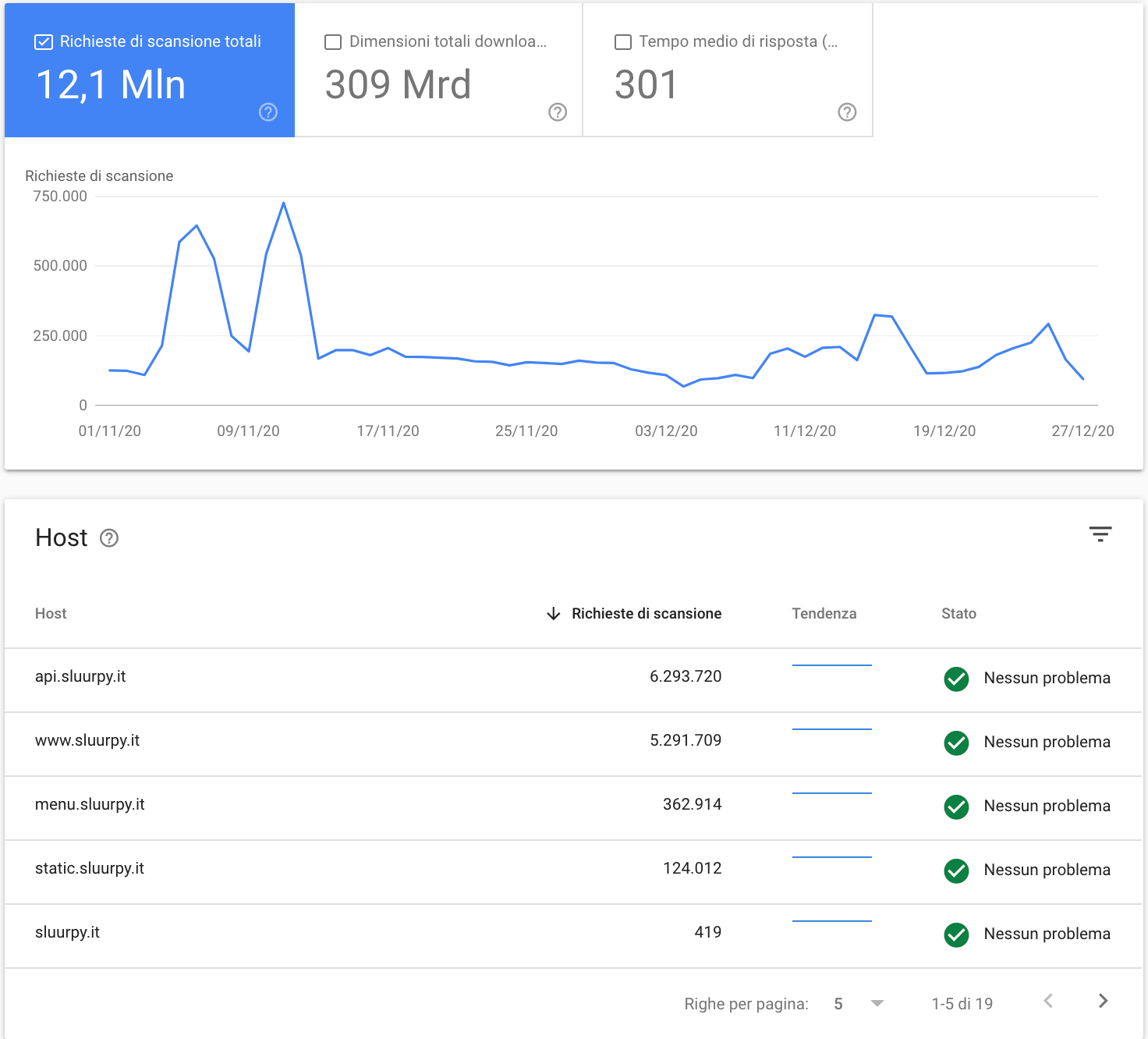
-
Ho fatto una scansione "veloce"... mi son fermato a 722 pagine...
Di queste
241 linkano a una pagina 404 "/s4/ristoranti+genova+ristorante/
16 sono 301 (di queste 301 ne hai ben 5 con 699 link ad esse)Hai poi una pagina con ben 4765 link.... praticamente una sitemap ! Perché esiste? ha qualche utilità per l'end user?
Secondo me qualcosa da mettere a posto c'è....
-
@mirkomassarutto che software hai usato?
Screaming frog ?
Grazie
1 Risposta
-
@bonzer1 No, Seo Powersuite Website Auditor, ed accesso con simulazione Google Mobile
Ma quello che ti ho segnalato dovrebbe dartelo anche screaming frog.. che è anche più leggero
-
@mirkomassarutto grazie e ottima notizia perché anche noi usiamo website auditor