- Home
- Categorie
- Digital Marketing
- SEO
- Spam engine
-
Spam engine
Lavoro da quasi un mese alla realizzazione di uno spam engine, nato per il concorso dei fattori arcani e che adesso sto espandendo.
Senza addentrarmi nel codice vi spiego cosa fa e poi vi parlo delle funzioni speciali che mi sono inventato.
Per prima cosa quando un utente chiama un url del tipo: nomeurlterzolivello.sito.est , viene letta la pagina www.sito.est (tipo mod rewrite, ma si tratta di altro).
Questa pagina controlla che l'url chiamato sia in archivio e se è così prende i dati che ha (testo, keywords da ottimizzare, metakey, metadescriptin, links, etc..), altrimenti li crea e li memorizza nel database. Per creare il testo uso il [url=http://www.giorgiotave.it/forum/viewtopic.php?t=4266]markov chain che ho migliorato esternamente..ovvero ho fatto in modo che potesse aprire + di 400kb di testi senza bloccarsi. Attualmente apre quasi 1,5 mb di testi, ma se volessi potrei apliarlo fino a 10mb e anche di più. Il problema sarebbe però un'eccessiva lentezza nel momento della creazione (se la pagina viene creata da google come spesso accade allora dipende dal tipo di connessione del loro spider ed essendo sicuramente alta non ci sono moltissimi problemi).
A questo punto apro il mio archivio di keywords e "ottimizzo" la pagina per una delle keywords scelte casualmente. Questo archivio di keywords è formato sia da keywords inserite manualmente da me tramite un semplice form, sia dall'insieme delle queries tramite cui gli utenti arrivano sul mio sito.
Questo fa in modo che lo spam engine punti di più sulle keywords più cercate e che contemporaneamente si espanda. In che modo? vi faccio un esempio:
- mettiamo che io abbia ottimizzato una pagina per la key "allevamenti cavalli roma" e che qualcuno arrivi da pagina 30 per la key allevamenti cavalli..il mio script creerà una pagina ottimizzata per quella key. Quindi si affinerà mano a mano che cresce.
Lo script inoltre prende una keywords a caso dall'archivio e linka la pagina keywordcasuale.sito.est che ovviamente qualora non esista viene creata.
Inoltre lo script controlla che l'url non sia nella forma pg856856..ovveronella forma pg[Numero]. Se l'url è in questa forma allora preleva il numero e linka alcune dele pagine successive.
Infine Lo script linka casualmente una pg[numero] da 0 a 15000 e in questo modo il sito cresce moltyo velocemente.
L'abbinamento tra sequenzialità e casualità infatti fa in modo che il sito cresca a macchie. Ovvero io inizio da pagina 1 e lo script linka alcune pagine successive..mettiamo quelle da 2 a 9. In più linka la pagina casuale tra 0 e 15000, mettiamo la pagina 8956. Lo spider leggerà queste pagine e farà queste 2 cose:
rafforzerà i link alle prime 9 pagine perchè le precedenti linkano le successive e in più creerà altre pagine successive alla 8956 e per ognuna di queste pagine linkerà un'altra pagina casuale. Nwel girò di una settimana google preleverà tantissime pagine. Attualmente ne prende tra le 500 e le 1500 al giorno.
Il difetto è nell'instabilità di questi link casuali che purtroppo a differenza dai link sequenziali non vengono memorizzati in archivio e quindi non garantiscono stabilità. Presto apporterò delle modifiche.
Un altra funzione molto interessante che ho creato e la funzione che si ispira in parte a quanto detto da agoago mesi fa: una pagina che non porta accessi è una pagina inutile.
Allora ho fatto in modo di abinare ad ogni pagina in archivio la data di creazione e ad ogni richiamo della pagina stessa viene controllato il numero di accessi a tale pagina. Dopo 5 giorni dalla creazione viene determinato il rapporto accessitotali/giornitotali..quanto questo rapporto scende sotto 1,2 allora la pagina è totalmente inutile e viene ri-ottimizzata per un'altra keywords. Questo finchè non porti almeno 12 visite ogni 10 giorni. Il numero peròè stato scelto un pò a caso nel timore di eliminare troppe pagine..ancora non so dirvi quanto sia valida questa funzione perché l'ho creata ieri e vedrò i primi risultati solo tra una settimana. In ogni caso penso che in futuro aumenterò almeno da 1,2 a 2 o 3.
Spero di avervi spiegato tutto. Che ne pensate? Avete altri suggerimenti?
P.S. come spesso detto se a qualcuno questo crea problemi può segnalare l'url dello spam engine a google (è uno di quelli che ho in firma mi pare), ma è pregato di avvisarci su giorgiotave.it. Questo perchè sarebbe interessate conoscere i tempi che intercorrono tra segnalazione e rimozione. Non dico che questo spam engine non sarà a scopo di lucro, ma nasce comunque per scopi di studio
")
-
Una domanda: il risultato che vuoi ottenere qual è ?
-
@uMoR said:
Una domanda: il risultato che vuoi ottenere qual è ?
Attualmente sto studiando i seguenti fattori:
- reazione di google ad un sito infinito
- reazione di google di fronte ad un sito con un bassissimo rapporto visitetotali/pagine
Inoltre mi interessa moltissimo scoprire i punti deboli di google e le sue reazioni ad uno spam engine..quali sono i tempi di reazione? e soprattutto una crescita esponenziale di pagine indicizzate non dovrebbe allarmare lo spider?
Ed infine: perché google non fa assolutamente niente per impedire che più risultati di uno stesso dominio siano presenti in una serp sebbene sottoforma di differenti siti di terzo livello?
Però la domanda che veramente mi interessa è una: qual'è il rapporto tra google e i frattali? Ovvero qual'è il rapporto che lega google ad una logica fatta di una precisa proporzione tra matematica e caos.
In fondo google non sa assolutamente cosa è una pagina di qualità. Google usa delle statistiche mischiate a algoritmi e dunque ciò che piace a google deve avere le sembianze di un oggetto frattale.In sostanza sono un alchimista alla ricerca del sito filosofale
")
-
Ho cercato anche io di rispondere a domande tipo le tue, l'unica conclusione "oggettiva" a cui sono arrivato è che fin tanto che hai valore sufficiente di poter fare immondizia G te lo permette, poi ti banna.
"quali sono i tempi di reazione?"
Dipende cosa intendi per tempi di reazione. All'inizio calcolavo bannato\non bannato, poi ho cambiato in faccio accessi\non faccio accessi\bannato.
Questo perchè è inutile avere 5 milioni di pagine indicizzate se non fai accessi giusto ? Non conta quante pagine hai in cache, conta quanti accessi fai..In generale però posso dirti che se fai dello spam palese, su un sito nuovo, per essere bannato impieghi 3 mesi. Se hai avuto fortuna a scegliere il dominio giusto e il server giusto nel primo mese puoi aspettarti anche qualche accesso, ma devi avere fortuna.
Su un sito vecchio dipende: i tempi si allungano ma non di molto, diciamo 3-4 mesi in più, però il vantaggio di un sito vecchio è che ti bastano pochi mesi per fare più di quanto quel sito ti possa rendere in qualche anno.
"e soprattutto una crescita esponenziale di pagine indicizzate non dovrebbe allarmare lo spider?"
Si, ma non in maniera "decisiva". Se tu fossi un motore di ricerca daresti tutto il peso ad un singolo algoritmo ? Sarebbe stupido.
Quindi praticamente spariamo una cifra a caso, G ha 100 algoritmi che decidono le serp. L'algoritmo per "il numero di pagine" ti assegna 1 punto negativo, gli altri 99 filtri 1 punto positivo, morale il tuo sito ha un punteggio pari a 99. Sopravvivi e fai un pacco di accessi ugualmente."perché google non fa assolutamente niente per impedire che più risultati di uno stesso dominio siano presenti in una serp sebbene sottoforma di differenti siti di terzo livello? "
Questa condizione non la verifico spesso nelle ricerche che effettuo però se ci basiamo sulla teoria del DNS avrebbe un suo senso teorico.
Ogni sottodominio può corrispondere ad un sito differente con ip differente server differente nazionalità differente ecc ecc.. Allora perchè non mettere in serp siti differenti ?Esempio stupido, altervista.
Se su altervista sono hostati gratuitamente spariamo 5000 siti, e 10 parlano di "cani pazzi" e meritano di essere nelle prime 10 posizioni per la chiave "cani pazzi", perchè non dovrei metterli tutti uno dietro l'altro in serp ? Teoricamente i sottodomini sono siti diversi..In senso più generale però risponderei così a questa domanda:
perchè gli algoritmi di G reputano che quei sottodomini meritino di stare in quella posizione."qual'è il rapporto tra google e i frattali?"
A pelle ti direi nessuno. Perchè ? Perchè rientra tutto in casi statistici.
Per esempio ti sei mai chiesto perchè nel porno in serp vedi solo spam che in altri settori viene bannato prima di essere messo online ?
Perchè tutti fanno spam.. Quindi G associa al porno -> spam."- reazione di google ad un sito infinito"
Ti banna prima.."- reazione di google di fronte ad un sito con un bassissimo rapporto visitetotali/pagine "
Cioè tu dici 100.000 visite per 100.000 pagine (quindi un teorico 1 visitatore per pagina) oppure 100.000 visite per 10 pagine ?Ad ogni modo, il tuo sito ha un tot di accessi preimpostati. G agisce di conseguenza..
-
@kerouac3001 said:
.... qual'è il rapporto che lega google ad una logica fatta di una precisa proporzione tra matematica e caos
Premetto innanzitutto che vado di pari passo con quanto risposto da uMoR.
Per quanto riguarda il rapporto tra metematica e caos non posso non pensare che anche per G valgano le stesse regole che si studiano a scuola.
Il caos, nel breve tempo, non esiste. Se consideriamo il caos a lungo termine come derivante-figlio di un caos a breve termine anche lui non ha motivo di essere definito tale.
Nel momento stesso in cui concepisco-penso-teorizzo una natura disordinata-dinamica-imprevedibile stabilisco che questa natura non esiste, paradossalmente.
Prevedendo che esista l'imprevisto, l'imprevisto cessa di esistere, in quanto previsto.
Teorizzando il disordine rinchiudo-pongo lo stesso in un universo composto da ordine e disordine. Un'antitesi che di fatto annulla entrambi.
Annullandosi a vicenda danno come risultato lo zero, e pertanto non potro' che cercare una risposta nei numeri positivi o negativi, numeri al di fuori dello zero.
A questo punto si potrebbe discutere di uno dei valori intrinsechi dei numeri negativi come simbolo di speranza-desiderio, dei positivi come simbolo di certezza.
Oggi ho comprato 3 chili di mele.
Mi mancano 200 euro (-200) e poi ho finito di pagare il mutuo...Ma tralasciamo questo aspetto e torniamo ai motori.
Nel web tutto diviene, si evolve, cambia costantemente, in modo disordinato e non prevedibile (o difficilmente prevedibile) pertanto e' realmente un caos. Per capirci un casino, un grosso casino...
Regole predertimate in un contesto random possono dar vita ad un frattale, ma considerare il web come frattale significherebbe voler misurare 2 o piu' dimensioni con la sola lunghezza.
Per i motori il web ha 4 dimensioni.
Ipotizziamo che l'altezza sia misurata-calcolata come numero di informazioni presenti in una pagina di un sito.
La larghezza e' il numero di pagine di un sito.
La profondita' e' il rapporto che intercorre tra il sito e gli altri siti (link).
Il tempo, quarta dimensione, e' il divenire-svilupparsi-cambiare, in un dato periodo, del contenuto delle pagine del sito, del loro numero, dei siti (numero, qualita') che hanno rapporti con lo stesso, ecc ecc
Il motore prende atto del "caos" e poi basandosi sullo stesso lo condiziona, cosi' che si snaturi.
Stabilendo che in serp si sale, per una data key, se la poni nel titolo, il motore suggerisce un ordine ben preciso a suo uso e consumo, cosi' che il web-caos divenga nel tempo piccino piccino.
Il motore ci dice che se un sito tratta di viaggi potra' guadagnare sfruttando 10.000 inserzionisti, se tratta di biglie al massimo 1 o 2.
Pertanto, troppi siti di viaggi, nessuno di biglie...
Kerouac3001 scrive:
"...ciò che piace a google deve avere le sembianze di un oggetto frattale"
Perfetto, e qui ci siamo in pieno.
Le societa', soprattuto se quotate in borsa, se devono rispondere agli azionisti, se devono corrispondere un dividendo, ecc ecc devono conciliare botte piena e moglie ubriaca.
Un mondo-web frattale a loro va benissimo, e' un mondo caotico ma gestibile se lo si spinge verso una sola dimensione, la lunghezza.
Siti fotocopia, stessi argomenti, stessa ottimizzazione, stessi inserzionisti, stessa distribuzione degli accessi dal motore in base al loro valore teorico.
Siti istituzionali, siti famosi, siti storici, poi siti belli, siti nuovi, ecc ecc
Di fatto un frattale, una figura che si ripete all'infinito dal grande all'infinitesimale piccolo. Dall'istituzionale al nuovo...
Loro ordinano, riducono-condizionano il tutto come se tutto fosse un frattale, cosi' che il cda possa azzeccare le previsioni dei dividendi con bassissimo margine di errore.
Se vuoi visibilita' devi apparire nei motori ai primi posti.
Se vuoi essere tra i primi nelle serp devi rispettare i dictat dei motori.
Se rispetti i dictat diventi frattale, parte piccola o grande che sia.
Se diventi frattale sarai autosomigliante, nel tempo e nello spazio, a tutti gli altri frattali.Sono uno, nessuno e centomila, ed inveendo contro spammer ed hacker rafforzano e rimarcano l'appartenenza ed il presunto predominio "naturale" del loro mondo, un mondo ad una dimensione.
Cerchi il sito filosofale?
Beh, niente di piu' facile. Dimenticati i motori, dimenticati le ottimizzazioni, dimentica il pr, fregatene dei temi ad alta resa.
Fai si che il tuo sito condizioni i motori e non viceversa.
Anticipali, non inseguirli.
-
Il caos, nel breve tempo, non esiste. Se consideriamo il caos a lungo termine come derivante-figlio di un caos a breve termine anche lui non ha motivo di essere definito tale.
Io dico che è il contrario. Nel breve tempo non esiste ordine nel caos. Nel lungo tempo esiste un ordine che regola il caos. Questo però è un ordine analizzabile a posteriori, mentre per le previsioni future i dati ottenuti solo attendibili solo se applicati nel breve termine. Vedi le previsioni del Meteo: analizzo i dati del tempo per anni, faccio tutti i calcoli, uso formule avanzatissime e teorie ancora più avanzate e con tutta probabilità ti posso assicurare che tra 5 minuti forse non piove.
Regole predertimate in un contesto random possono dar vita ad un frattale, ma considerare il web come frattale significherebbe voler misurare 2 o piu' dimensioni con la sola lunghezza.
Capisco ciò che vuoi dire, ma sinceramente non mi piace come l'hai detto. Ovvero, immagino tu voglia dire che analizzare soltanto l'aspetto frattale del motore non ci da alcuna informazione utile su come sia meglio operare sul posizionamento di un sito. D'altra parte analizzare 2 o più dimensioni con una sola lunghezza è esattamente il compito di un frattale, quindi se si vuole fare un'analisi in funzione di questo è una regola che va accettata. Quindi se il mio scopo non è migliorare il posizionamento, ma studiare il web come frattale, allora non c'è miglior modo che usare una sola lunghezza per analizzare più dimensioni.
Il motore prende atto del "caos" e poi basandosi sullo stesso lo condiziona, cosi' che si snaturi.
Probabile
Ma non è necessario che il motore ne prenda atto affinché esso esista. E inoltre è si probabile che il motore voglia condizionare il caos affinché si snaturi (in modo da impedire il reverse engeenering), ma d'altra parte il caos è la fotografia del motore di ricerca in quanto tale e quindi snaturarlo è impossibile.
Se vuoi visibilita' devi apparire nei motori ai primi posti.
Se vuoi essere tra i primi nelle serp devi rispettare i dictat dei motori.
Se rispetti i dictat diventi frattale, parte piccola o grande che sia.
Se diventi frattale sarai autosomigliante, nel tempo e nello spazio, a tutti gli altri frattali.....
Cerchi il sito filosofale?
Beh, niente di piu' facile. Dimenticati i motori, dimenticati le ottimizzazioni, dimentica il pr, fregatene dei temi ad alta resa.
Fai si che il tuo sito condizioni i motori e non viceversa.
Anticipali, non inseguirli.Se rispetti i dictat non diventi frattale..diventi parte del frattale e condizioni i motori..condizioni quindi il frattale.
Comunque tutto questo ci assicura una sola cosa..il frattale regola uno degli aspetti più importanti di cui i motori devono tenere conto: la moda e l'evolversi di essa.
Quindi l'analisi delle SERPs in quanto parti di un oggetto frattale ci possono dare un'ottima idea della moda.
-
kerouac3001 forse ora ho capito meglio cosa intendi e cosa ricerchi.
Quando io parlavo del caos a breve termine mi riferivo appunto al web ed al rapporto con i motori.
Essendo il web di oggi, di ogni giorno, sempre figlio del web di ieri (si evolve, non subisce in ogni momento un effetto random puro) rimarcavo che un caos nel web (inteso come caos a caso) non esiste, ma parliamo appunto di un caos deterministico, quello appunto che tu vuoi misurare o cercare di riprodurre con i frattali.
Premesso questo, che credo sia la base comune per proseguire, dopo divagavo-cazzeggiavo (perche' e' proprio dalle discussioni ingolfate che vengono fuori gli spunti migliori) che e' simpatico che si possa definire caotico qualcosa di riproducibile magari con i frattali in quanto se determino il caos esso stesso di per se' non e' piu' cas. Sono discussioni filosofiche di bassa lega, ma che possono essere utili.
Se 100 pazzi irrompono nel campo durante una partita si produce caos, ma il caos e' per chi vede da fuori l'invasione, per per chi la produce, come dico loro sono il frattale, o meglio come dici tu loro sono parte del frattale, ma nel suo disordine quel caos e' "ordinato" dalla loro scelta di invadere il campo, nel momento stesso in cui uno da lo spunto all'invasione il caos prodotto di per se non e' piu' caos perche' prodotto da una scelta, magari istintiva, ma pur sempre scelta, di creare caos.
E' il caso del web, e' un caos deterministico e a me non piace chi definisce il caos come deterministico. Ma visto che si usa cosi' tanto vale mi ci adeguo ovviamente, era una disgressione.
Ora veniamo al punto. Tu dici, il motore prende atto di un web-caos, il motore in quanto ordina e cataloga questo caos deterministico e' riproducibile frattalmente.
Dici, me ne frego delle 4 dimensioni, ne uso una la lunghezza, misuro il tutto e poi vedo se riesco a riprodurre la fotografia che un motore ha-da del web in modo frattale, magari anche in 3d visto che lo possi fare con i frattali.
Dici, giustamente, me ne frego che questo possa o meno avvantaggiare un posizionamento, e' comunque uno studio molto interessante dal punto di vista "scientifico".
Io ricordo che essendo il motore stesso parte del frattale e condizionante nella formazione dei futuri frattali il risultato sara' un immagine di un frattale-motore e non del frattale-web puro.
Ma giustamente tu avevi premesso che ti interessava il motore-frattale e non altro, e pertanto questa considerazione giustamente non inficia minimamente il valore della tua ricerca.
Poi, proseguendo nel discorso affermi che se si rispettano i dictat non di diventa frattale ma parte dello stesso, condizionandolo.
Ecco qui diciamo la stessa cosa per la prima parte, in quanto affermo che si diventa frattali intendo appunto parte del frattale, nessuna pretesa che un sito possa diventare "il" frattale.
Sul secondo aspetto invece, quello che facendo parte di un tutto automaticamente si vari la figura stessa che ci rappresenta, non sono molto d'accordo, ma anche questo e' solo per motivi tutti miei poco matematici.
E' il solito albero che cade e nessuno lo vede, e' caduto?
Ovviamente si ma di fatto non lo e'. Se anni fa uno scienziato avesse inventato una cura definitiva contro il cancro, ma se la fosse portata nella tompa, senza pubblicarla, chi potrebbe di noi affermare che esiste o esistera' in futuro con certezza questo fenomenale rimedio?Bene cosa c'entra quanto sopra con il motore-frattale?
Un frattale che si riprodice all'infinito presentera' sempre delle parti cosi' piccole, di dimensione cosi' vicine allo 0 che per quanto uno si sforzi di "vederle" loro si presenteranno man sempre in forma cosi' infinitesimale che solo la teoria ci fa sapere che esistono, ma non le potremo "vedere" in modo tangibile.E' la geniale intuizione del Gap di Marshall
Ora so, cosa mi risponderesti, mi diresti che il motore pero' e' un qualcosa di finito, non di infinito, in quanto per dire, e' formato da un tot di pagine archiviate e catalogate.
Ecco di questo discutiamo.
Il motore cambia la sua figura di frattale per ogni key che rappresenta il suo mondo, il mondo.Un numero altissimo di key singole, di key formate da 2, 3 ,4, ecc parole, infinite combinazioni di key che danno infinite figure di frattali...
Ma ammettiamo che uno calcoli tutte le possibili combinazioni di parole, per formare tutte le key possibili.
In previsione di questo il motore si difende e ci fa vedere solo una parte infinitesimale della sua figura per ogni data key, magari solo i primi 1000 risultati su centinaia di milioni a sua disposizione.
Tutti gli altri risultati, tutti gli altri frattali che lo compongono, non ci vengono mostrati. Non esistono per noi, sono alberi che cadono e nessuno ne puo' prendere coscienza.
Sei in serp ma non appari, ma ci sei alla 1.000.326 posizione....
Esisti in teoria, come esiste in teoria la parte infinitesimale del frattale infinito, ma di fatto non ne condizioni la figura, in quanto parte non visibile.
Ora, ti prevengo, tu mi dirai che a te interessa misurare, riprodurre il frattale visibile, quello composto key per key dai soli risultati mostrati, gli unici che di fatto "esistono" per tutti noi.
Perche' e' proprio questa realta' ben tangibile che ci condiziona, che "fa" la moda, che ci impone di mettere ora una key qui ed ora levarne una la'. Ora sviluppare un dato argomento ora abbandonarlo, ecc ecc
Indubbiamente. E' un'ottima intuizione.
Ora devi stabilire come riuscirci, come lavorare su questo progetto.
Per farlo in modo corretto si dovrebbe tenere conto dell'aspetto dinamico del web e degli algoritmi utlizzati dai motori.Il motore aumenta i propri algoritmi proprio in base al divenire del web e ne modifica efficacia e valori.
Se assumo una certa medicina subiro' alcuni effetti, se ne assumo assieme 2 diverse l'associazione produrra' effetti diversi, ci sono inibitori, catalizzatori, ecc ecc
Lo stesso vale per gli algoritmi, una key nel titolo aiuta, se la metto anche 20 nel body posso essere penalizzato. Se mettessi 20 volte una key nel body e non nel titolo probabilmente la passerei liscia, chi fa spam ha la brutta abitudine di "ottimizzare" tutto e ovunque, ed i motori lo sanno, da qui i ban....
Insomma, non so se sono stato chiaro, solo il motore stesso potrebbe darci le sue immagini frattali, con una certa approssimazione, ma sarebbe gia' qualcosa.
Farlo dall'esterno e' cosa dura, ma questo non significa che non possa dare buoni spunti o si scopra cose impensabili.
Spero che tu riesca!
-
Inizio anch'io a capire il tuo punto di vista..però devo risponderti su alcuni punti.
@agoago said:
E' il caso del web, e' un caos deterministico e a me non piace chi definisce il caos come deterministico. Ma visto che si usa cosi' tanto vale mi ci adeguo ovviamente, era una disgressione.
Non credo che si possa definire il caos deterministico. Come dicevo prima ciò che ci insegna la Teoria del Caos è che molti degli eventi che da sempre abbiamo definito come casuali non lo sono affatto. Un oggetto frattale come dici bene anche tu è l'output di un sistema governato da casualita e causalità. In sostanza mentre prima pensavamo al caos come disordine adesso lo pensiamo come un disordine ordinato. Il caos dunque è disordine che tende all'ordine man mano che si va verso l'infinito.
Tempo fa mentre studiavo queste teorie, mi sono divertito a prendere tutti i risultati delle estrazioni del lotto per una ruota e ad applicarvi una formula ricorsiva, la stessa formula che si applica per generare il triangolo di sierpinski e che ho riscritto in modo da applicarla al lotto.Triangolo di Sierpinski
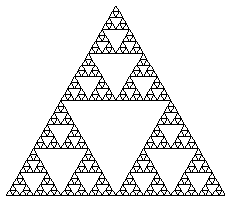
Ne è uscita fuori una figura a 90 lati che aveva un suo ordine interno. Questo mi ha permesso di sapere che numeri sarebbero usciti il giorno dopo? No. Non era nemmeno lo scopo. Si, la teoria del caos è usata per fare previsioni a breve termine, ma il caos non è deterministico..io so cosa verrà fuori in generale..se mi dai 10000 numeri usciti al lotto io so che applicandovi una data formula uscirà fuori una data struttura, ma si tratta di un determinismo macroscopico..è come dire: il 2006 sarà un anno molto piovoso per l'europa. Questo non impedisce alla sicilia di non vedere una sola goccia d'acqua.
In sostanza il frattale è un oggetto con un determinato livello di libertà il quale gli permette di fare quello che vuole purché all'infinito tenda verso una figura precisa. In sostanza il frattale di sierpinski e quello del lotto sono due sistemi di libertà vincolati dall'equiprobabilità.
@agoago said:
Sul secondo aspetto invece, quello che facendo parte di un tutto automaticamente si vari la figura stessa che ci rappresenta, non sono molto d'accordo, ma anche questo e' solo per motivi tutti miei poco matematici.
E' il solito albero che cade e nessuno lo vede, e' caduto?
Ovviamente si ma di fatto non lo e'. Se anni fa uno scienziato avesse inventato una cura definitiva contro il cancro, ma se la fosse portata nella tompa, senza pubblicarla, chi potrebbe di noi affermare che esiste o esistera' in futuro con certezza questo fenomenale rimedio?Bene cosa c'entra quanto sopra con il motore-frattale?
Un frattale che si riprodice all'infinito presentera' sempre delle parti cosi' piccole, di dimensione cosi' vicine allo 0 che per quanto uno si sforzi di "vederle" loro si presenteranno man sempre in forma cosi' infinitesimale che solo la teoria ci fa sapere che esistono, ma non le potremo "vedere" in modo tangibile.E' la geniale intuizione del Gap di Marshall
Ora so, cosa mi risponderesti, mi diresti che il motore pero' e' un qualcosa di finito, non di infinito, in quanto per dire, e' formato da un tot di pagine archiviate e catalogate.
Mi spiace agoago
sono totalmente in disaccordo con questo tuo discorso. Non so su cosa si basa la tua affermazione per la quale secondo te le parti piccole non possano modificare sensibilmente l'output frattale del motore, sarà che sono comunista, ma io vedo un grandissimo potere nelle piccole cose. Un albero che cade in una foresta, può far dimettere berlusconi domani stesso. E' la teoria di Lorenz (uno dei primi studiosi a parlare di Teoria del Caos) secondo cui: il battito d'ali di una farfalla in Thailandia può scatenare un tornado in Messico.Questa non è un'idea campata in aria ed è invece il punto centrale della teoria del caos..ovvero la propagazione dell'informazione, la propagazione dell'errore. Se io avessi miliardi e miliardi di sensori che misurino 1 sola volta tutti i dati necessari ad un'accurata previsione metereologica e li disponessi in modo che ognuno sia a 10 centimetri dall'altro (in altezza, larghezza e profondità) e in modo che tutta la terra ne fosse ricoperta, potrei dare una previsione precisa solo per le seguenti 12 ore. Dopo di che l'errore inizierebbe a propagarsi in modo esponenziale e certamente il giorno dopo la mia previsione sarebbe meno attendibile e così via. Perché? in fondo avevo tantisimi dati..avevo una temperatura media su 10cm cubi su tutta la terra. Eppure la propagazione dell'errore è così veloce e cresce esponenzialmente, rendendo il caos un fenomeno indeterministico, nonostante goda di un ordine.
Quindi secondo me ogni sito cambia il frattale-motore, cambiandone anche solo impercettibilmente la moda.
Adesso tu mi dirai: certo come no, se fosse così tutte le serp cambierebbero radicalmente giorno dopo giorno. Io invece dico che non è questo il punto..il punto è che ogni sito sconvolge il frattale-motore e lo trasforma..certamente non vedrai grandissimi cambiamenti analizzando una sola serp il giorno dopo, ma l'informazione si propaga in modo tale da scatenare un domino di effetti. Quindi il piccolo sito non conta zero, ed è anzi importantissimo.
@agoago said:
Insomma, non so se sono stato chiaro, solo il motore stesso potrebbe darci le sue immagini frattali, con una certa approssimazione, ma sarebbe gia' qualcosa.
Farlo dall'esterno e' cosa dura, ma questo non significa che non possa dare buoni spunti o si scopra cose impensabili.
Spero che tu riesca!
Sei stato chiarissimo. Io non mi pongo nessun obiettivo minimo. Cercherò inizialmente di analizzare la reazione del motore nei confronti del mio spam engine "sensore" e nei primi mesi provvederò unicamente a migliorare lo script inserendo piccole regole in modo che sembri un sito del tutto naturale.
La sovraottimizzazione di cui parli tu è uno dei problemi principali che dovrò studiare.
P.S. nonostante non sia d'accordo con te su alcuni punti, preciso che non sono d'accordo solo con le tue affermazioni di carattere strettamente matematico..questo perché ho delle teorie (teorie di altri per la maggior parte) che seguo e che mi mettono in contrasto con alcune tue dichiarazioni. Invece mi sono utilissimi i tuoi suggerimenti di carattwere SEO-informatico
-
Forse stiamo riuscendo a trovare una strada comune, a forza di spiegarci.
C'e' caos e caos, che caos...
Per esempio, da wikipedia.org: http://en.wikipedia.org/wiki/Chaos_theory
In mathematics and physics, chaos theory deals with the behavior of certain nonlinear dynamical systems that under certain conditions exhibit a phenomenon known as chaos. Among the characteristics of chaotic systems, described below, is a sensitivity to initial conditions (popularly referred to as the butterfly effect).
As a result of this sensitivity, the behavior of systems that exhibit chaos appears to be random, even though the model of the system is deterministic in the sense that it is well defined and contains no random parameters. Examples of such systems include the atmosphere, the solar system, plate tectonics, turbulent fluids, economies, and population growth.
Systems that exhibit mathematical chaos are deterministic and thus orderly in some sense; this technical use of the word chaos is at odds with common parlance, which suggests complete disorder.
In poche parole, c'e' caos caotico e caos deterministico, c'e' un caos basato sul random ed un caos (deterministico) basato su basi ben definite e senza parametri random.
Altro spunto interessante: http://www.ba.infn.it/~zito/ds/chaos.html
There are four possible ways to get chaos:
-
Ignorance:this is labeled as "external influences". If you don't know what's happening than the result will be "surprising" and thus chaotic.
-
Many simple systems interacting in space:you know well how the single system behaves but the overall result can be surprising and thus chaotic. The simplest case is cellular automata. In this case interaction in space is essential to have chaos .
-
One single system developing in time:also here if the law is recursive than the result (after some time) can be surprising and thus chaotic. Time in this case is essential to get chaos.
-
Use a quantum system like a radioactive material:the law is then intrinsically chaotic. There is no way to know when exactly a radiactive substance will decay.
In case 2 and 3 we speak of deterministic chaos i.e. chaos in presence of well known and simple laws
Dallo stesso sito, in italiano finalmente:
"Da notare che questo tipo di caos prodotto da algoritmi semplici non va confuso col caso dove non esistono algoritmi per riprodurre i risultati osservati:ad esempio i risultati del lotto.
Per distinguere i due casi si parla di caos deterministico quando esso e' prodotto da leggi semplici e di "caso" quando l'unico algoritmo possibile e' quello di enumerare tutti i risultati ottenuti senza che sia possibile prevedere quelli futuri. "
Come dici tu, la tua figura del lotto non permette di prevedere numeri, neanche lontanemante, in quanto caos non detreministico, viceversa per le previsoni del tempo si tratta di un evento malamente determinabile, pertanto deterministico.
Quello che contesto a questi dotti e' l'uso improprio del termine caos associato al termine deterministico. Se il battito d'ali mi determina un uragano allora si che si parla di caos! Ma se analizzo anni di dati e faccio una discreta previsione meteo, e dico che piove in tutta italia e poi solo a catania fa bello che razza di caos e'?
E' una previsione con un buon margine di errore, fine... ma vah beh, questo non c'entra con il nostro discorso....
Secondo aspetto, e qui diciamo la stessa cosa ma con una chiara avvertenza da parte mia.
"Quindi secondo me ogni sito cambia il frattale-motore, cambiandone anche solo impercettibilmente la moda."
E ci mancherebbe, sono stra concorde!
Ma attenzione, la moda cambia! ma essendo che il motore non ci mostra che 1000 dei miliardi di sensori possibili, non potremo capire chi e come lo ha cambiato.
Capisci, non contesto che non si cambi, anzi, ne sono certo, sono certo che una sola pagina potrebbe cambiare 10 algoritmi di un motore e tutte le serp del mondo in un sol secondo, ma noi non sapremo mai dell'esistenza di quella pagina, pertanto ci chiederemo sempre se il tifone sia stato prodotto da un battito d'ali, uno starnuto o da un'esplosione.
Non potendo vedere noi quella pagina, non sapremo cosa ha determinato la modifica del frattale-motore e pertanto per noi sara' "solo" l'ennesima variazione della figura del frattale rispetto la precedente.
Il motore ha "miliardi e miliardi di sensori" ma noi analizzando il motore ne vedremo 1000, pertanto non solo noi non vediamo l'uomo che fara' la differenza, ma per di piu' il motore, volutamente, ci nasconde interi continenti, tutto il mondo facendoci vedere come giudica solo 1000 uomini, uomini presi sull'intera popolazione!
Pertanto non ne faccio minimamente una questione politica o filosofica ma prendo atto di una realta' che non mi piace, quella di tenere nascoste le informazioni affinche' si possa governare tranquillamente forti dell'ignoranza prodotta.
Ed i 3 grossi motori fanno cosi', lo hanno sempre fatto, cambiano le serp a seconda degli ip, dei browser, ci mettono dentro un po' di spam cosi' da illudere che lo si possa ancora fare e poi dopo 6 mesi bannano milioni di siti straottimizzati, scrivono falsita' nelle loro faq che regolarmente smentiscono in parte nei fatti, e via discorrendo.
Pertanto non solo per cercare di capire che tempo fara' a roma o a new york ti e' permesso di analizzare solo il meteo su 10 ettari nelle Ande, ma per di piu' c'e' un signore che decide, a seconda di come gli pare e piace, di cambiare metro per metro il clima su quei 10 ettari delle Ande per indurti a pensare che domani forse piovera' a roma ma fara' bello a new york.
Pertanto sarebbe bellissimo se la tua anlisi risultasse, anche solo in minima parte, utile a smascherare i giochini dei soliti furbi (motori), e ti bacerei senza remora mani e piedi. Lo dico in tutta serieta'.
Del resto come si suol dire, chi non sospetta l'insospettabile non scoprira' mai la verita'. E di certo a questo mira il tuo progetto, verita' piccola o grande che sia.
-
-
@agoago said:
Del resto come si suol dire, chi non sospetta l'insospettabile non scoprira' mai la verita'. E di certo a questo mira il tuo progetto, verita' piccola o grande che sia.
Adesso devo capire come fare ciò che voglio fare..su cosa basarmi.
Inizialmente pensavo: faccio uno spam engine perché ha 2 cose positive: si espande velocemente e occupa diverse serp.
Poi mi son reso conto che era inutile farlo malamente, perché intanto rischio (come dicevi tu una volta) che ci siano milioni di pagine inutili (non visitate e dunque "penalizzanti"), e inoltre anche riuscendomi a posizionare bene vedrei tutto dall'ottica di uno spam engine e in ogni caso avrei a disposizione pochissimi dati da analizzare.Adesso penso che se voglio veramente partire con un'analisi approfondita del frattale dietro al motore, dovrei creare un'estensione firefox.
Un'estensione installabile da chi vuole partecipare al progetto e che memorizza le ricerche fatte su google estrapolandone tutti dati utili.Ma finora per quanto bello e utile resterebbe un semplice progetto di statistica. Per carità molto interessante, ma ciò che preme maggiormente a me è appunto l'aspetto frattale e per quello sarebbe necessario individuare il giusto modo di analizzare i dati.
La domanda vera è: avrò il tempo necessario per farlo? Ma forse non è nemmeno questo l'importante..già solo studiando il metodo si possono imparare tante cose.
Per esempio quali sono i dati utili?
Se faccio un'estensione firefox potrebbe seguire questo algoritmo:
se viene effettuata una ricerca su google esegui le seguenti azioni:
a) preleva la query
b) preleva il numero di risultati
c) preleva il numero di risultati con l'allinanchor
d) preleva il numero di risultati con l'allintitle
e) preleva i risultati e la loro posizione
f) preleva il pr dei risultati
g) preleva i link che puntano ai risultati
h) preleva i link in uscita dai siti dei risultatiE questa sarebbe solo una piccolissima parte dei dati interessanti, perché quelli realmente interessanti o sono difficili da prelevare o sono impossibili da prelevare.
Con lo spam engine invece non trovo il frattale, ma trovo un modo per adattarmi al frattale..insomma faccio un'analisi al contrario.
Per esempio mi sono accorto d'aver fatto un errore gravissimo e molto stupido: avevo inserito link soltando a domini di terzo livello interni al mio dominio. Quindi il mmio dominio aveva solo pagine di questo tipo: nomepagina.sito.est. Questo però ha creato diversi problemi:- il dominio risultava unicamente composto da domini di terzo livello e immagino che google abia algoritmi che penalizzino una struttura del genere.
- senza pagine interne normali la struttura risultava molto fragile.
Quindi ho risolto il problema inserendo una percentuale molto alta di pagine interne.
Purtroppo questo non può nemmeno essere considerato un test vero e proprio perché le variabili analizzate non sono le uniche che influiscono sul risultato finale.
In ogni caso i lati positivi di usare uno spam engine per fare analisi sono due:
- la possibilità di applicare delle regole armoniche a tutta la struttura e non solo ad una parte
- la possibilità di potersi permettere un ban da google senza eccessivi rischi.
Forse la soluzione migliore è quella di usare sia un analisi statistica attraverso un'estensione firefox e poi una volta analizati i dati applicarli alla struttura dello spam. Ma sarebbe anche utile creare un motore che analizzi le serp in cerca della moda, per poi utilizzarla nella struttura dello spam engine.
Insomma, il progetto risulta veramente complesso e complicato.
-
Molto bella Kerouac3001 l'idea della t.b. per firefox.
Forse inizialmente avrebbe vita dura perche' le t.b. non son ben viste e poi sapendo che la t.b. passa dati sulle ricerche effettuate potrebbe avere parecchi denigratori.
Tuttavia, se i dati raccolti fossero pubblici... anonimi, in tempo reale, postati su un sito a libero accesso... diventerebbe uno strumento potenzialmente molto efficace per "contrastare" ed individuare molte strategie dei motori... potrebbe prendere piede mica male, magari privilegiando gli accessi ad alcune "analisi approfondite" a tutti quelli che la usano, come dire dati pubblici ma le analisi solo a chi aiuta...
Si, potrebbe funzionare davvero, mi sa di ideona tutto sommato, una t.b. che si "attiva" solo quando un utente va suoi motori e passa i dati al server centrale che li aggiorna e propone in tempo reale, con stat ecc ecc... beh risponderebbe veramente all'idea di un grande fratello positivo, creato non per spiare e condizionare ma per distribuire e condividere liberamente le informazioni tra tutti, smascherando mistificazioni e dati taroccati del furbo di turno.
Niente da dire, complimenti, idea fantastica.
Per quanto riguarda gli spam engine, in base ad anni di test, posso dirti che le pagine inserite nei db sono in proporzione al valore del sito, gli accessi sono in base al valore del sito, il valore dei messaggio pubblicitari dipendono dal valore del sito, ecc ecc
Si puo' non far scendere il valore di un sito, difficilmente forzarlo.
Per non farlo scendere usa strutture random, in tutto.
Peso pagina, testi, codice, livelli, link, colori, immagini, data dei file, errori (link, html, ecc ecc... un sito senza errori e' un sito automatico) e via dicendo.
Allora lo prendono e qualcosina rende.
Tutto qui il trucco, per quel che puo' valere.
-
Sono partito con la creazione dell'estensione.
Attualmente ho fatto questo: ho preso l'estensione pagerankstatus (quella che mostra il pr nella statusbar) e l'ho modificata.
La scelta è caduta su questa estensione per 3 motivi:- non sono abbastanza bravo da fare una estensione partendo da zero
- l'estensione si attiva quando avviene il load della pagina (esattamente ciò che serve a me)
- infine in questo modo posso fornire un servizio utile, ovviamente non per ingannare l'utente fingendo che l'estensione si occupi di altro, ma per renderla più interessante. Nel progetto è prevista un'ampia spiegazione di ciò che viene fatto e il codice sarà (ovviamente) pubblico e verificabile da tutti.
Attualmente l'estensione preleva solo l'url della pagina se questo è un url di google e precisamente un url del search|news|images|groups, i dati vengono passati ad una pagina php che si occupa di analizzarli per evitare piccoli problemi (tipo l'invio molteplice degli stessi dati in un breve lasso di tempo, dovuto al modo in cui viene richiamato l'evento load dal javascript)
Infine vengono memorizzati salvando precisamente:query
url base di google (tipo www.google.ii/search)
hl
lr
paginaVolevo salvare anche risoluzione e link della serp, ma non mi riesce. Purtroppo non sono bravissimo, ma piano piano lo miglioro.
Tra un pò lo faccio installare ad amici così lo testiamo..quando avrò raggiunto un livello accettabile partirò con un progetto pubblico che prevederà la possibilità di partecipare alla raccolta dati, alla creazione di aggiornamenti periodici e all'analisi dei dati ottenuti.
-
Aggiornamento:
adesso l'estensione salva i link della serp in questo modo
campo serp: tutti i link assieme
link1: primo link
link2: secondo link
...
link10: decimo linkOvviamente se start è diverso da 0 link1 corrisponde al primo link di quella pagina quindi 1+start...etc..
Inoltre ho creato una funzione che salva l'url del link cliccato tra quelli della serp e anche la sua posizione. Quindi se io cerco pippo e per esempio decido di cliccare sul 13° risultato, allora lui aggiunge alle informazioni sulla ricerca effettuata anche il link cliccato su quella serp.
Più semplicemente:
- io cerco topolino e non trovo nulla in prima pagina. Nonostante ciò ovviamente sul db viene salvata la ricerca effettuata a pagina 1 della key topolino, la serp relativa, la lingua usata etc..
- decido di andare a pagina 2 e ovviamente vengono subito salvati i dati della ricerca
- do un'occhiata ai link e decido che il 17° fa al caso mio e così ci clicco. Ai dati salvati nel 2) passaggio vengono aggiunte le seguenti info:
- link cliccato (url del link)
- posizione assoluta del link cliccato (17)
Questo ci permetterà in futuro di analizzare percentuali di interesse generale per ogni posizione e varianza rispetto ad un url specifico.
Intendo dire che potremo sapere in generale quali sono le percentuali di click per ogni posizione e che grazie a questi dati potremo stabilire l'interesse dell'utente intorno ad un sito specifico.Esempio: mettiamo che la percentuale di click media per la 12° posizione sia dell'1% ed un mio sito per una determinata query si trovi alla 12° posizione e su 1000 visualizzazioni riceva molti più click della media generale. Questo mi fornirebbe dati intorno a:
- pertinenza del title
- pertinenza della description
- fama del sito
- e si potrebbe pure stabilire se un sito è o no una risorsa utile (se lo è certamente la sua percentuale sarà maggiore, perché gli utenti si fidano e vanno sul sicuro)
Questo renderebbè l'estensione non solo uno strumento di analisi della serp, ma anche uno strumento utile all'analisi del sito.
-
@kerouac3001 said:
Non credo che si possa definire il caos deterministico.
Il caos è deterministico. Ad esempio, un sistema fisico che obbedisce alla Meccanica Classica (quindi è deterministico) può benissimo essere caotico.
In un sistema caotico, le traiettorie nello spazio delle fasi che corrispondono a variazioni infinitesimali delle condizioni iniziali, divergono esponenzialmente. Da qui l'imprevidibilità di un sistema caotico (deterministico).
Se vuoi giocare con l'indeterminismo devi scendere ai livelli della Meccanica Quantistica (caos quantistico). Ma penso che non c'entri con google
-
@extrabyte said:
Il caos è deterministico. Ad esempio, un sistema fisico che obbedisce alla Meccanica Classica (quindi è deterministico) può benissimo essere caotico.
In un sistema caotico, le traiettorie nello spazio delle fasi che corrispondono a variazioni infinitesimali delle condizioni iniziali, divergono esponenzialmente. Da qui l'imprevidibilità di un sistema caotico (deterministico).
Se vuoi giocare con l'indeterminismo devi scendere ai livelli della Meccanica Quantistica (caos quantistico). Ma penso che non c'entri con google
Aggiungo: per poter stabilire la caoticità di google, bisogna costruire l'appropriato spazio delle fasi.
In ogni caso, una condizione sufficiente è la presenza di una dinamica non-lineare. Un classico esempio è dato dalla trasformazione quadratica.
Esempio: x è un input che viene processato dando l'output y, che poi viene mandato in feedback nuovamente come input. Se y segue la legge y=ax (dove a è una costante numerica positiva), allora il sistema non è caotico in quanto è lineare. Se invece è y=ax-ax^2, allora qui abbiamo una dinamica quadratica (perciò non lineare) ed è proprio questa che innesca il caos. Difatti la y=ax-ax^2 è caotica e simula la crescita di una popolazione in un ambiente a risorse finite, mentre la y=ax simula la crescita di una popolazione in un ambiente a risorse infinite.Cosa c'entra tutto questo con google? IMHO, se l'algoritmo di un motore di ricerca prevede processi iterativi con una dinamica non-lineare, allora è sicuramente caotico....