- Home
- Categorie
- Digital Marketing
- SEO
- GUIDA: come usare Google Spreadsheet per fare scraping a fini SEO
-
GUIDA: come usare Google Spreadsheet per fare scraping a fini SEO
Ho deciso di scrivere questa breve guida (ma a mio avviso utile) per rispondere ad una esigenza particolare che ho riscontrato parlando con chi si occupa di SEO da qualche anno e non è più un principiante.
Poniamo il caso di avere già una lista pronta di 300 URLs e aver bisogno di conoscerne il tag <title> per fare le nostre considerazioni.
Per svolgere questo compito, abbiamo sostanzialmente 3 opzioni:
- Usare un servizio API esterno (probabilmente a pagamento)
- Creare il nostro web scraper in Python o Go
- Senza saper programmare né acquistare crediti per utilizzo di API, possiamo scrivere una semplice formula in Google Spredsheet.
Analizzando la terza soluzione, basta usare una XPath query (in questo caso //title) all'interno della formula:
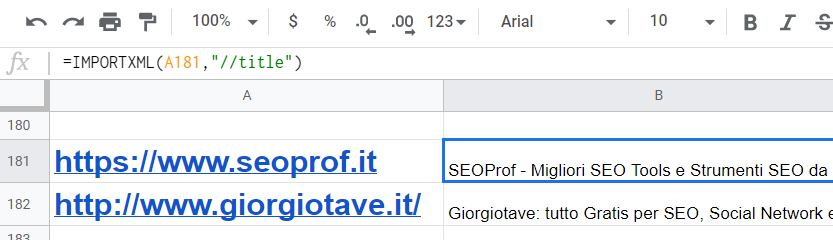
=IMPORTXML(A2;"//title")
Riporto un esempio di uso di questa formula applicata a 2 URLs.
Utilizzando le XPath queries ci sono moltissimi altri utilizzi possibili in chiave SEO.
Potremmo voler recuperare la meta description e sarà sufficiente usare la seguente formula:
=IMPORTXML(A2;"//meta[@name='description']/@content")
Se invece ci servisse il tag H1, basterà usare:
=IMPORTXML(A2;"//h1")
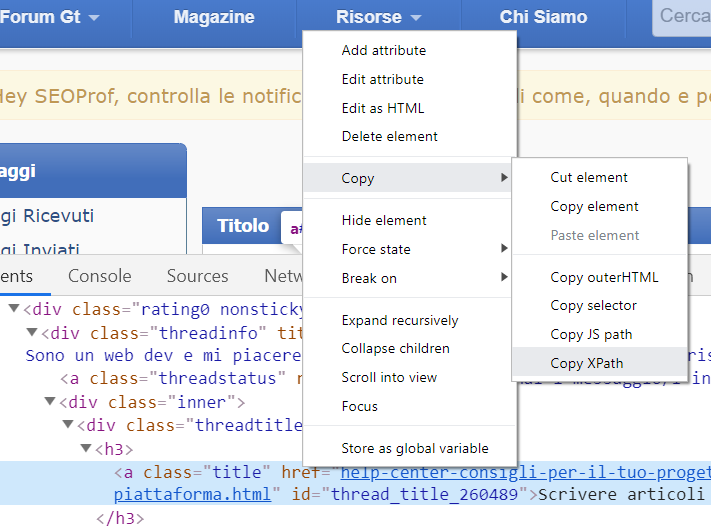
E se volessimo estrarre un tag particolare, quale query andrebbe usata?
Ci viene in aiuto Google Chrome, perché basta selezionare l’elemento che ci interessa nella pagina e poi andare su “Ispeziona elemento > Clic con tasto destro > Copia > Copia XPath”. In questo modo abbiamo davvero una grande flessibilità nell’estrare quello che ci interessa dalla pagina.
Spero che queste funzionalità possano facilitare il lavoro SEO di qualche lettore se non ne fosse ancora a conoscenza.

-
Ciao
grazie per gli ottimi spunti, ma l'opzione 4? Il fantastico coltellino svizzero Screaming Frog? Basta incollare le url ed escono tutte le info che servono e non solo il Title.
-
Screaming Frog è un ottimo software, ma il vantaggio di Google Spreadsheet è di avere tutto nella stessa schermata, senza fare export e import tra software diversi.
Soprattutto possiamo anche mettere condizioni per vedere a colpo d'occhio se una pagina HTML contiene una determinata keyword e ordinare i risultati, ma si può fare molto molto altro.
Insomma si può dare spazio alla creatività all'interno di un'unica schermata.
D'altra parte Screaming Frog è nativamente progettato per il crawling e (per questioni di performance) probabilmente è preferibile nel caso di progetti con migliaia e migliaia di URLs da scansionare.
-
Questa è un'ottima risorsa, grazie
")
Dovremmo fare un topic in rilievo per raccoglierle tutte